 Introducción
Introducción
 DevOps se ha convertido en una estrategia de transformación digital para muchas empresas. Se trata de una filosofía para lograr la colaboración de los equipos de desarrollo y operaciones, así como las mejores prácticas para la automatización de procesos en un entorno de desarrollo de software y administración de sistemas.
DevOps se ha convertido en una estrategia de transformación digital para muchas empresas. Se trata de una filosofía para lograr la colaboración de los equipos de desarrollo y operaciones, así como las mejores prácticas para la automatización de procesos en un entorno de desarrollo de software y administración de sistemas.
En la era moderna, cada vez hay mayores retos que exigen la integración de nuevas herramientas de software para tratar con los microservicios, contenedores (Docker, kubernetes), así como la mayoría de los servicios de tecnologías de información en una organización, y para solucionar estos retos operativos es donde entra GitOps, pero primero hay que dividir la palabra Git/Ops para comprender mejor este proceso (Weaveworks, s.f.).
Git es un sistema distribuido de control de versiones que administra el código fuente con el cual se trabaja localmente o en colaboración con otros desarrolladores. Por otro lado, el término Ops son las operaciones que se llevan a cabo en la compilación, implementación, operación y monitoreo en el desarrollo de aplicaciones.
Explicación
Definición de GItOps
 GitOps es un proceso que es utilizado en la fase de despliegue continuo de las aplicaciones en la nube. La herramienta que se utiliza es Git para la infraestructura operativa. Es un marco operacional y se necesitan las mejores prácticas de DevOps para su correcto funcionamiento.
GitOps es un proceso que es utilizado en la fase de despliegue continuo de las aplicaciones en la nube. La herramienta que se utiliza es Git para la infraestructura operativa. Es un marco operacional y se necesitan las mejores prácticas de DevOps para su correcto funcionamiento.
GitOps es una combinación del código como infraestructura, automatización de los procesos de integración y despliegue continuo (CI/CD), así como el conjunto de solicitudes que son utilizados para la gestión del cambio en las aplicaciones.
La idea principal de GitOps es tener repositorios usando la herramienta Git para llevar un control de versiones que optimicen la infraestructura en el entorno de pruebas, así como lograr la automatización de los procesos en el entorno de producción. Si se necesita actualizar o realizar cambios en una aplicación, solo se tiene que actualizar el repositorio o repositorios del proyecto, los procesos automatizados se encargaran del resto, impactando de manera significativa en la reducción de tiempos y costos en la administración del sistema como en los despliegues de la aplicación.
La implementación de este proceso beneficia a las organizaciones de las siguientes maneras:
- Seguridad y cumplimiento: algunas de las herramientas utilizadas en este proceso te permiten administrar los permisos de usuarios para evitar robos o pérdida de información en el código fuente o en los entregables.
- Mejora en la experiencia del desarrollador: los desarrolladores utilizan una herramienta familiar y confiable, como lo es Git, para administrar otras herramientas como, por ejemplo, kubernetes, incrementando la productividad.
- Confiabilidad: con Git disminuyen los riesgos ocasionados por una caída del sistema, ya que los repositorios están alojados en la nube o por errores en las aplicaciones, ya que se puede revertir la versión del código fuente, impactando en la reducción de tiempo y en la recuperación de los servicios o fallas en las aplicaciones.
- Consistencia: todo el flujo de trabajo tiene una infraestructura consistente, tanto en el modelo de la aplicación como en la gestión administrativa.
- Implementación rápida: gracias a la automatización del despliegue continuo en conjunto con un control en el ciclo de retroalimentaciones se pueden desplegar las aplicaciones rápidamente.
- Entornos autodocumentados: el historial completo de todos los cambios realizados en la aplicación y los detalles de los despliegues se tendrán en el sistema y se pueden revisar en la rama maestra (master branch); esto ayuda en el trabajo colaborativo y comparte las lecciones aprendidas a los nuevos miembros del equipo.
El proceso para la canalización (pipeline) de GitOps es a partir de las solicitudes de cambios realizados por los usuarios. Dichos cambios se ven reflejados en el repositorio de la herramienta Git. Después se crea una imagen de un contenedor y es empujado al registro de contenedores. Al terminar el registro, el contenedor es actualizado por un configurador de actualizaciones (config updater); el siguiente paso es cuando los usuarios realizan una solicitud para fusionarlo en una rama diferente realizando un despliegue a la misma. Ahí se realizan las pruebas pertinentes para saber si todo está funcionando correctamente; entonces el supervisor, al dar el visto bueno, lo vuelve a fusionar en la rama principal para las pruebas finales. Por último, si pasa las pruebas, se procede al despliegue y actualización de servicios.
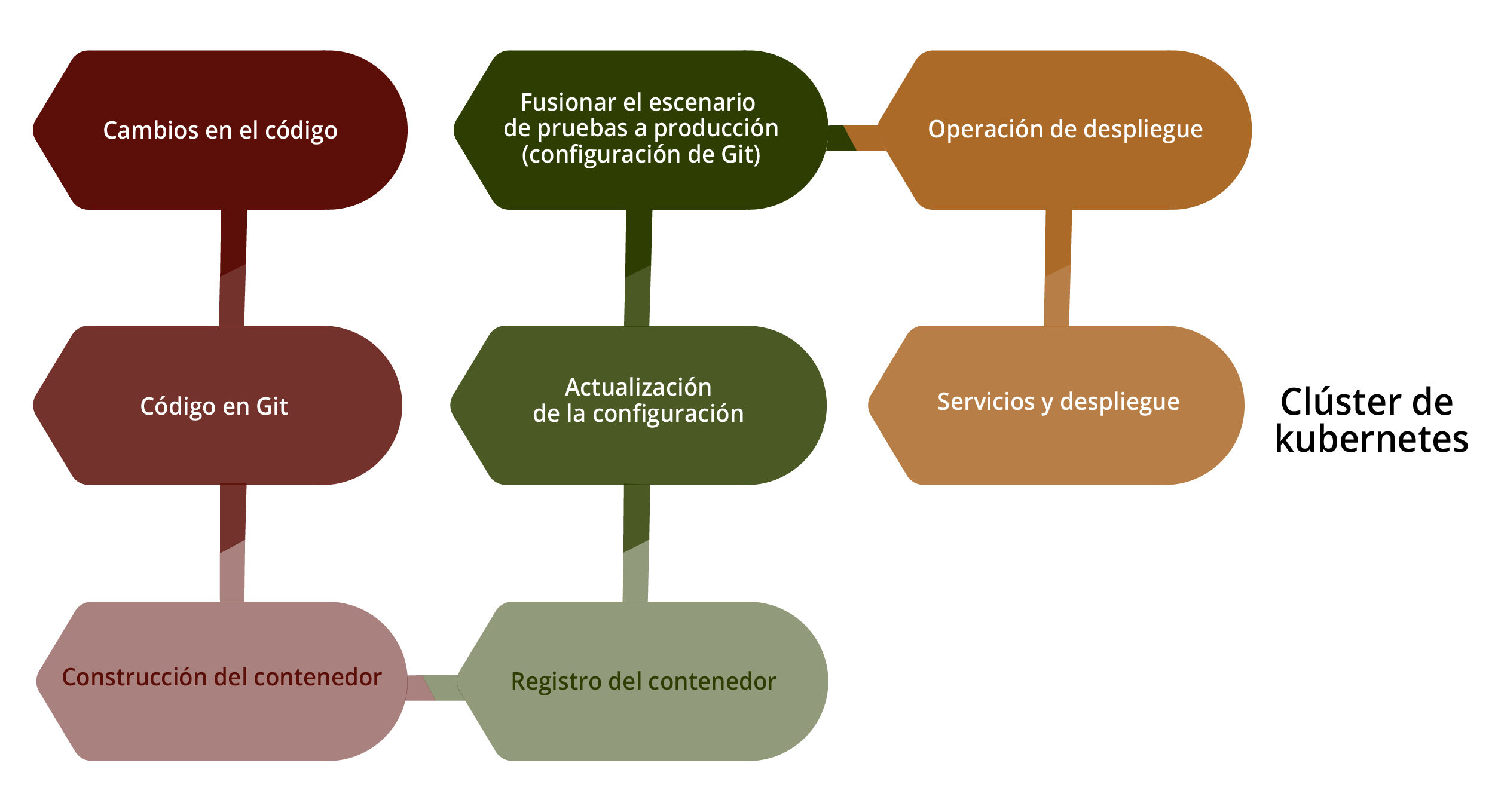
Figura 1. Proceso de canalización de GitOps.
Arquitectura e instrumentación de GitOps
El tener una buena instrumentación en los procesos de GitOps ayuda a obtener una integración continua (CI), sólida e intuitiva. El sistema CI puede activar scripts basados en eventos de git, pero aún necesita herramientas sólidas para impulsar esos scripts y garantizar que se puedan ejecutar y mantener de manera fácil y segura. La implementación de cambios de código (también conocida como entrega continua (CD), es uno de los pasos más desafiantes para automatizar, por lo que a continuación se mencionan algunas herramientas que te ayudan en estos procesos.
Los contenedores con Docker y kubernetes son dos herramientas que operan a nivel de contenedores y no de hardware; ambas son una plataforma de contenedores, de microservicios y son portables en la nube. Ahora conocerás cada una de ellas, según Docker (s.f.):
- Docker lanzó el desarrollo de la nube a un panorama distribuido completamente nuevo y ayudó a los desarrolladores a comenzar a considerar de manera realista las arquitecturas de microservicios como una opción viable. Parte de lo que hizo que Docker fuera tan poderoso fue su facilidad de uso para desarrolladores en comparación con la generación anterior de soluciones de virtualización.
Al igual que las configuraciones de CI declarativas que se encuentran dentro de los repositorios, los desarrolladores simplemente tienen que escribir y mantener un Dockerfile en su repositorio para permitir compilaciones de contenedores automatizadas de VM (Virtual Machine) desplegables. La creación de contenedores es una táctica enormemente poderosa para los equipos nativos de la nube y debería ser una herramienta básica en su repertorio.
- Kubernetes/k8s ofrece muchas funcionalidades, ayuda a optimizar los flujos de trabajo y acelera los tiempos de desarrollo. Esta plataforma es popular por que tiene una arquitectura sólida y, como es escalable, permite a innumerables equipos de desarrollo entregar y mantener el software mediante la automatización basados en contenedores. Muchas organizaciones ya están usando esta plataforma para construir su arquitectura en la nube y ofrece sus propias distribuciones como AWS Servicio de contenedores elásticos para kubernetes, motor de kubernetes en Google y servicio kubernetes en Azure.
Existen otras herramientas que, en conjunto con Docker o kubernetes, ayudan a que las operaciones sean más sencillas y la arquitectura más sólida. Por ejemplo:
- Flux: es un operador de GitOps kubernetes y fue desarrollado por los creadores de GitOps.
- GitKube: es una herramienta para construir y desplegar imágenes de Docker, empujándolas a kubernetes usando Git.
- JenkinsX: despliegue continuo en kubernetes con construcción en GitOps.
- ArgoCD: operador de GitOps para kubernetes con una interfaz web.
Por otra parte, existen soluciones de infraestructura como código (IaC) como Terraform, CloudFormation y otras. Estas soluciones permiten a los desarrolladores describir los otros bits de una aplicación, como los recursos de kubernetes, los equilibradores de carga, las redes, la seguridad y más, de forma declarativa. Al igual que las configuraciones de CI y los Dockerfiles, todos los desarrolladores del equipo pueden controlar la versión y colaborar con las plantillas de IaC (Thor, 2021).
Con esta infraestructura tienes archivos que son de configuración con las especificaciones necesarias que facilitan la distribución y edición de las configuraciones; de esta manera se preparan siempre los mismos entornos. El control de versiones es clave en IaC y se deben de aplicar a los archivos de código fuente, así como a los de configuración.
Al automatizar esta infraestructura, la preparación de los servidores, almacenamiento y los sistemas operativos ya no necesitan gestionarse ni realizar configuraciones manualmente optimizando el tiempo de desarrollo.
Existen dos tipos de enfoques: el declarativo y el imperativo. El enfoque declarativo es el más utilizado, ya que se prepara la infraestructura deseada de manera automática. En cambio, el otro enfoque requiere que una persona resuelva cómo se debe de aplicar la preparación de la infraestructura.
La preparación de la infraestructura siempre había sido un proceso manual largo y costoso. En la actualidad, su gestión ha dejado de lado el hardware físico en los centros de datos, aunque todavía puede formar parte de los elementos de la empresa, pero en general se ha optado por la virtualización, los contenedores y el cloud computing.
Algunas de las ventajas de la Infraestructura como Código (IaC) son las siguientes:
- Reducción de costos.
- Disminución de errores en la configuración.
- Infraestructura más sólida.
- Implementación más rápida.
Estas son algunas herramientas que se utilizan para gestionar la configuración y automatización de servidores para lograr la IaC:
- Puppet
- Chef
- Saltstack
- Terraform
GitOps se centra en la mejora y automatización de la infraestructura de tecnologías de información utilizando la herramienta Git como repositorio central para el control de versiones y así, los archivos de configuración describen los recursos que se desean provisionar y como resultado se obtiene una evolución en el estado de la infraestructura.
Principios y flujo de trabajo de GitOps
Para poder administrar el grupo (clúster) con los flujos de trabajo de GitOps se necesita seguir los principios que se describirán a continuación:
- El estado canónico deseado del sistema de versiones Git
- Cambios aprobados que se pueden aplicar automáticamente en el sistema
- Agentes de software para asegurar la corrección y alertar sobre divergencias
 1. Todo el sistema se tiene que describir con un enfoque declarativo
1. Todo el sistema se tiene que describir con un enfoque declarativoUn ejemplo de esto es utilizando la herramienta kubernetes, pero tienes que recordar que existen más herramientas nativas de la nube que son declarativas y que pueden ser usadas mediante código, guardando las versiones de las declaraciones de las aplicaciones en Git. Entonces tendrás una sola fuente con información veraz y confiable. Estas aplicaciones pueden ser desplegadas de una manera sencilla y se puede retroceder hacia kubernetes o viceversa, pero lo más importante es cuando se tienen errores que provocan un mal funcionamiento en la aplicación, ya que toda la infraestructura puede volver a ser reproducida rápidamente.
Con las declaraciones del sistema guardadas en un sistema de control de versiones (Git) y que sirva como una sola fuente de información, se tendrá un solo lugar en donde todo se deriva y se pueda manejar. Se puede utilizar Git para revertir cualquier aplicación a un estado anterior garantizando la seguridad del sistema; también se pueden utilizar llaves SSH para asegurar aún más la autoría de donde procede el código y sus cambios.
Ahora que ya se tienen las declaraciones en el estado canónico (estandarizado) deseado en Git, el siguiente paso es permitir cualquier tipo de cambio a ese estado para que sean automáticamente aplicados en el sistema. Lo que se tiene que recalcar es que no es necesario que el grupo tenga credenciales para realizar los cambios. Con GitOps se tiene un ambiente segregado en el cual se pueden realizar ajustes por fuera del sistema y después fusionarlos en la rama principal, de esta manera se pueden separar los cambios que se están realizando y cómo los están realizando.
Una vez que ya está declarado el sistema y mantienes con un buen control de versiones, los agentes del software empiezan a informar cuando la realidad de lo que se está haciendo no cumple con las expectativas deseadas. El uso de estos agentes asegura que todo el sistema esté siempre en buen estado. Pueden ocurrir errores, como en el caso de un error humano; en estos casos los agentes de software actúan como control iterativo y de retroalimentación para las operaciones.
GitOps ayuda a tener un mayor control sobre los cambios de las aplicaciones. Además, permite administrar múltiples clústeres para varios clientes. Los despliegues por medio de CI/CD típicos no se pueden comparar con el uso de GitOps y pueden ser utilizado tanto por los administradores como por los desarrolladores.
Una tubería (pipeline) típica de GitOps
 Puede decirse que las canalizaciones (pipelines) de GitOps se dividen en dos partes: integración continua (CI) y despliegue continuo (CD), las cuales se verán a detalle:
Puede decirse que las canalizaciones (pipelines) de GitOps se dividen en dos partes: integración continua (CI) y despliegue continuo (CD), las cuales se verán a detalle:
-
1. Integración continua: es una práctica en el desarrollo de software en la cual los desarrolladores fusionan los cambios de los códigos en un repositorio central (Git). Con cada cambio se automatiza la construcción y las pruebas del código y provee retroalimentaciones a los desarrolladores quienes realizaron el o los cambios. La diferencia de la integración continua de GitOps al de la tradicional es que también se actualiza el manifiesto de la aplicación por medio de la nueva versión que se genera después de la construcción y las pruebas.
- Despliegue continuo: es la práctica de la automatización en el proceso de liberación del software. El despliegue continuo incluye el aprovisionamiento de la infraestructura que es adicional al despliegue. Lo que hace diferente al del despliegue continuo tradicional de DevOps es que utiliza un operador de GitOps para monitorear y de esta manera manifestar los cambios y orquestar un buen despliegue. Siempre que el despliegue continuo esté completo y el manifiesto actualizado, el operador de GitOps se hace cargo de los despliegues eventuales.
Los objetivos de una canalización CI/CD son una serie de etapas con tareas muy específicas:
- Productividad: provee retroalimentaciones que son de mucho valor para los desarrolladores en términos de diseño, estilo de código y calidad de todo el contexto y también mejoras en los análisis de códigos, pruebas de integración, y seguridad.
- Seguridad: detecta vulnerabilidades en el código por medio de análisis cada intervalo de tiempo.
- Escalabilidad: descubre las cuestiones de escalabilidad antes de la integración a la producción mediante las pruebas por unidad y funcionales. Lo que no detectan estas pruebas son las fugas de memoria y de hilos.
- Tiempo de comercialización: ofrece funciones a los clientes con rapidez. Con una canalización CI/CD completamente automatizada, los trabajos manuales que requieren tiempo ya no existirán para las implementaciones del software. Las publicaciones del código se realizan en cuanto se pasan todas las etapas del proceso.
- Reporteo: monitorea continuamente y mejora la ejecución de la canalización, el tiempo de producción se mejorará, así como las métricas del proceso.
La canalización completa de la integración continua GitOps tiene las siguientes tres grandes fases:
- Etapas de pre-compilación (prebuild): a estas etapas se les conoce como etapas de análisis estático y son una combinación de escaneos manuales y automatizados del código antes de su compilación y empaquetado en una imagen del contenedor.
- Solicitud de extracción/revisión del código (pull request/code review).
Todas las canalizaciones CI/CD deben de empezar con una solicitud de extracción, la cual ayuda a la revisión y coherencia del código entre el diseño y la implementación y así detectar posibles errores. - Sobre el análisis de vulnerabilidades, las librerías que son de fuente abierta (open source) pueden traer defectos y vulnerabilidades o problemas de licencias. Lo mejor es integrar un software que analice estas librerías, por ejemplo, la herramienta Nexus vulnerability scanner se usa para remediar los problemas por medio de la actualización de las librerías o usar otras librerías alternativas.
- El análisis de código es excelente para la coherencia entre el diseño y la implementación, estándares de codificación y duplicado de código; aunque este análisis es manual, existen herramientas para facilitar la revisión como SonarQube. Este no reemplaza la revisión, pero puede detectar problemas de una manera efectiva.
- Etapas de compilación (build): después del análisis estático, ya es tiempo de compilar el código, crear la imagen del contenedor, las pruebas de unidad (módulo) y la efectividad de las pruebas, ya que son partes integrales de la construcción.
- La etapa de compilación empieza con la descarga de las librerías necesarias antes de la actual compilación, después el binario generado y las bibliotecas deben empaquetarse en una unidad ejecutable (como jar o war en Java) para la implementación.
- Las pruebas de módulo (unit test) son para revisar que una parte del código hace lo que debe hacer. Este código no debe de tener dependencias externas al código que se está probando. De esta manera se revisa la funcionalidad individual del módulo, así se evitan problemas que surgen cuando el módulo interactúa con otros módulos. Para eliminar los problemas de dependencias, las llamadas externas suelen ser simuladas para reducir el tiempo de ejecución de las pruebas.
- En la etapa de cobertura de código se mide el porcentaje del código que está en ejecución por las pruebas automatizadas del módulo. La cobertura del código es una parte importante de la retroalimentación en el proceso de desarrollo, ya que resalta las partes del código que no funcionan como se esperaba y se requiere cambios para volver a realizar las pruebas. Este ciclo continúa hasta que el código es completamente funcional.
- En la etapa de compilación con Docker significa que una imagen de Docker es la unidad desplegable de kubernetes. Una vez que se ha compilado el código, puede crear la imagen de Docker con un Id (identificación) de imagen único para sus artefactos de compilación, creando un Dockerfile y ejecutando el comando de compilación de Docker. Esta imagen debe tener su convención de nomenclatura única y cada versión debe etiquetarse con un número de versión único. Además, también puede ejecutar una herramienta de escaneo de imágenes de Docker en esta etapa para detectar posibles problemas de vulnerabilidad con sus imágenes y dependencias base.
- En la etapa de empuje con Docker, la imagen de Docker recién construida debe publicarse en un registro de Docker para que kubernetes organice la implementación final. Un registro de Docker es una aplicación del lado del servidor. Para el desarrollo interno, la mejor práctica es alojar un registro privado para tener un control estricto sobre dónde se almacenan las imágenes.
- En la fase de repositorio de configuración de clones de Git, suponiendo que la configuración de kubernetes se almacena en un repositorio separado, se realiza un clon de Git para copiar la configuración de kubernetes en el entorno de compilación para la etapa posterior y, de esta manera, actualizar el manifiesto.
- En la fase de actualización de manifiestos, cuando ya se tienen los manifiestos en el ambiente de compilación, se pueden actualizar los manifiestos con el Id de la imagen recién creada. Para esto se tiene que utilizar una herramienta de administración de la configuración, por ejemplo, Kustomize.
- En la etapa de Git mandar y empujar (commit and push), ya que se actualizaron los manifiestos, solo quedaría enviarlos al repositorio de Git. La canalización de CI está completa, el operador de GitOps detecta los cambios en los manifiestos e implementa los cambios en kubernetes.
- En las etapas de post-compilación, ya que se completaron las etapas de CI de GitOps, son necesarias las siguientes fases para obtener información de las métricas para la mejora continua, los reportes para las auditorías y para notificar a los equipos de trabajo el estatus de avance de la compilación.
Lo siguiente es publicar las métricas de CI. Las métricas de CI son las siguientes: - Integración continua (CI): si se lleva mucho tiempo en las compilaciones, tanto la productividad como los equipos de trabajo se verán afectados y la reducción en el porcentaje de la cobertura de código puede aumentar la cantidad de defectos en la producción. Por eso es conveniente tener reportes históricos de los tiempos de compilación y las métricas de los porcentajes de la cobertura del código para que los equipos puedan monitorear las tendencias y, de esta manera, incrementar la cobertura del código y disminuir el tiempo de compilación.
- Problemas en la compilación: los equipos de desarrollo necesitan datos que sean confiables y relevantes para que se puedan clasificar los defectos de compilación y resolver las fallas que se presenten en las pruebas de los módulos.
- Requisitos de cumplimiento: incluye la información de compilación, los resultados de las pruebas, quién realizó la publicación y qué se publicó y debe de mantenerse almacenado de uno a siete años.
- Etapas de GitOps CD son etapas lógicas que son llevadas a cabo por el operador de GitOps para los despliegues basados en los cambios de los manifiestos.
- Repositorio de configuración de clones de Git.
- El operador de GitOps detecta los cambios en el repositorio y crea un clon en Git para obtener los últimos manifiestos del repositorio.
- Análisis de manifiestos.
- El operador de GitOps determina si se tiene un delta (varianza/diferencia) entre los manifiestos de kubernetes y los del repositorio en Git; si no hay diferencia, el operador se detiene en esta etapa.
- Aplicación de Kubectl.
- En esta etapa del despliegue continuo de GitOps en donde se aplica Kubectl se determinan las diferencias entre los manifiestos del repositorio de Git y los de kubernetes; después, el operador aplica los nuevos manifiestos a kubernetes por el comando Kubectl aplicar (Kubectl apply). Kubectl es una línea de comandos que se ejecutan en los despliegues con kubernetes; estos comandos sirven para la comunicación con el clúster para realizar las operaciones.
- Mediante las pruebas de integración se revisa si los diferentes módulos están funcionando correctamente en conjunto. Una vez que la imagen es desplegada al área de QA (quality assurance), se procede a realizar estas pruebas en todos los módulos y sistemas externos como los servicios y las bases de datos. En esta etapa se descubren los problemas ocasionados por la interacción de todos los módulos y sus funciones que no pueden ser descubiertos en las pruebas unitarias.
- Vulnerabilidad en tiempo de ejecución. Son detectadas por las pruebas de penetración, también se les conoce como hacking ético y esta es la práctica en la cual se prueba un sistema, red o aplicación web para encontrar brechas de seguridad que pueden ser explotadas por algún ataque. Algunas de las vulnerabilidades son inyección de SQL, de comandos o cookies.
- Publicar las métricas de CD. Las métricas de CD son las siguientes:
- Problemas en la compilación: los equipos de desarrollo necesitan datos que sean confiables y relevantes para que se puedan clasificar los defectos de compilación y resolver las fallas que se presenten en las pruebas de los módulos.
- Requisitos de cumplimiento: incluye la información de compilación, los resultados de las pruebas, quién realizó la publicación, qué se publicó y debe de mantenerse almacenado de uno a siete años.
La canalización completa del despliegue continuo GitOps es la siguiente:
Etapas de post-despliegue: después de que la imagen es desplegada se procede a probar el código nuevo en contra de las vulnerabilidades y las dependencias.
La idea principal de GitOps es la de almacenar en un repositorio de Git toda la infraestructura declarativa de las aplicaciones. Con esto, los desarrolladores pueden enviar solicitudes de extracción y, de esta manera, agilizar los procesos de operación, implementación y mantenimiento de las aplicaciones de kubernetes.
 Cierre
Cierre
En la industria de TI GitOps están gobernando los microservicios y las plataformas de contenedores. GitOps se aprovecha para implementar aplicaciones en un entorno de contenedores como kubernetes, apoyado por Docker, y es una táctica para automatizar en DevOps. Esto quiere decir que los equipos de desarrollo trabajan de una manera colaborativa en Git y todos los procesos necesarios para llevar el código realizado a producción será automatizado por GitOps.
 Checkpoint
Checkpoint
Asegúrate de:
- Reforzar la diferencia entre GitOps y DevOps para reconocer la tubería típica y la tubería de GitOps.
- Aplicar el concepto de integración continua, en especial en las etapas de pre-compilación para la identificación de errores o cambios basados en las pruebas de las aplicaciones.
- Comprender el concepto de despliegue continuo para las mejoras continuas de los procesos.
- Reforzar el concepto de infraestructura como servicio, con énfasis en la creación y liberación de instancias de servidores para la obtención de información en tiempo real.
 Bibliografía
Bibliografía
- Docker. (s.f.). Kubernetes. Recuperado de https://www.docker.com/products/kubernetes
- Thor, D. (2021). A Developer's Guide to GitOps. Recuperado de https://www.architect.io/blog/gitops-developers-guide
- Weaveworks. (s.f.). Guide to Gitops. Recuperado de https://www.weave.works/technologies/gitops/
