Microsoft. (2020). Inicio rápido: Creación de un clúster de Apache Spark en Azure HDInsight mediante Azure Portal. Recuperado de https://docs.microsoft.com/es-mx/azure/hdinsight/spark/apache-spark-jupyter-spark-sql-use-portal
Microsoft. (2020). Tutorial: Carga de datos y ejecución de consultas en un clúster de Apache Spark en Azure HDInsight. Recuperado de https://docs.microsoft.com/es-es/azure/hdinsight/spark/apache-spark-load-data-run-query
Microsoft. (2020). Tutorial: Compilación de aplicaciones de aprendizaje automático de Apache Spark en Azure HDInsight. Recuperado de https://docs.microsoft.com/es-es/azure/hdinsight/spark/apache-spark-ipython-notebook-machine-learning
Notas:
- Esta aplicación utiliza los datos de ejemplo que se presentan en el archivo HVAC.csv, los cuales se encuentran disponibles en todos los clústeres de manera predeterminada. El archivo se encuentra en: \HdiSamples\HdiSamples\SensorSampleData\hvac
- Los datos de este archivo señalan la temperatura objetivo y la temperatura real de algunos edificios que tienen sistemas de calefacción, ventilación y aire acondicionado instalados. La columna System señala el identificador del sistema y la columna SystemAge el número de años que lleva este sistema (HVAC) alojado en el edificio.
from pyspark.sql import *
from pyspark.sql.types import *
Fuente: Microsoft. (2020). Tutorial: Carga de datos y ejecución de consultas en un clúster de Apache Spark en Azure HDInsight. Recuperado de https://docs.microsoft.com/es-es/azure/hdinsight/spark/apache-spark-load-data-run-query
# Create a dataframe and table from sample data
csvFile = spark.read.csv('/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv', header=True, inferSchema=True)
csvFile.write.saveAsTable("hvac")
%%sql
SELECT buildingID, (targettemp - actualtemp) AS temp_diff, date FROM hvac WHERE date = \"6/1/13\"
Una vez realizado, te mostrará la siguiente tabla:
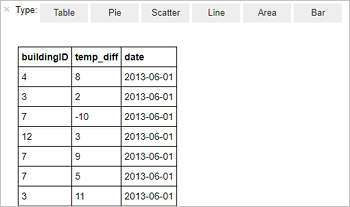
Fuente: Microsoft. (2020). Tutorial: Carga de datos y ejecución de consultas en un clúster de Apache Spark en Azure HDInsight. Recuperado de https://docs.microsoft.com/es-es/azure/hdinsight/spark/apache-spark-load-data-run-query