
 ¿Alguna vez te has preguntado como una red social puede identificar los gustos o preferencias de una persona o de qué modo una aseguradora sabe cuánto ofrecer a sus clientes?
¿Alguna vez te has preguntado como una red social puede identificar los gustos o preferencias de una persona o de qué modo una aseguradora sabe cuánto ofrecer a sus clientes?
Para dar respuesta a las cuestiones anteriores se necesita conocer la teoría de probabilidad y estudiar estadística. La relación entre ambas ha llegado a ocupar un lugar en la historia de la humanidad hasta el punto en que el genio matemático, Laplace, opinó que resulta increíble ver como algo que surgió del análisis sobre los juegos de azar hoy sea el objeto más importante del conocimiento humano.
Por otra parte, tanto la probabilidad como la estadística nos permiten establecer criterios inteligentes para la toma de decisiones al medir y conocer la incertidumbre. Devore (2019) comenta que, si la incertidumbre no formara parte de la realidad, los métodos estadísticos no serían necesarios o tan importantes como lo son desde el último siglo hasta la actualidad. Por ejemplo, resultaría difícil creer que, de cientos de miles de usuarios de una red social, todos compartieran exactamente el mismo gusto por las artes o los deportes.
Es así como la probabilidad y la estadística se consideran valiosas en distintos campos, entre ellos el análisis de datos y el aprendizaje automático, los cuales se introducen durante este tema.

¿Qué es estadística y probabilidad?

Gutman y Goldmeier (2021) explican que usualmente los términos probabilidad y estadística se emplean de manera indistinta, pero que, si se aborda con mayor detalle cada uno, es posible comprender la diferencia. Para lo anterior, Gutman y Goldmeier presentan un ejemplo simple: piensa en una gran bolsa con canicas dentro, cuyos colores desconoces. Tampoco sabes cuál es su forma o tamaño. Ni siquiera sabes cuántas hay en la bolsa, pero imagina que metes la mano y sin ver agarras un puñado. Realmente no tienes información sobre lo que tienes en la mano o en la bolsa. Entonces Gutman y Goldmeier señalan la diferencia: en probabilidad, descubres exactamente lo que hay en la bolsa y usas la información para adivinar lo que tienes en la mano. Mientras que, en estadística, abres la mano y usas la información para inferir qué hay en la bolsa.
Por su parte, Devore (2019) presenta la idea previa de una manera más formal; en un problema de probabilidad se asume que se conocen las características de la población que se está estudiando, lo que permite hacer preguntas y responderlas en relación con una muestra obtenida de tal población. Por otro lado, en un problema de estadística, se cuenta con información acerca de la muestra y, a partir de ella, se pueden deducir conclusiones sobre la población en cuestión.
De acuerdo con Gutman y Goldmeier (2021), la estadística a menudo se divide en descriptiva y en inferencial. Probablemente estés familiarizado con la estadística descriptiva aun sin conocer el término, algunos ejemplos pueden ser números que resumen datos: los números que lees en el periódico o ves en una pantalla de directivos (ventas promedio del último trimestre, tasas de desempleo, etc.). Medidas como la media, la mediana, el rango, la varianza y la desviación estándar forman parte de la estadística descriptiva y se requiere de fórmulas específicas para su estimación.
Ahora, cuando se toma tal información y se procede a hacer suposiciones para inferir el contenido general de toda la población, se trata de estadística inferencial.
Así, la relación entre ambas disciplinas se resume diciendo que la probabilidad se basa en un razonamiento deductivo, mientras que la estadística inferencial trabaja con razonamiento inductivo. Lo anterior se ilustra en el diagrama 1:
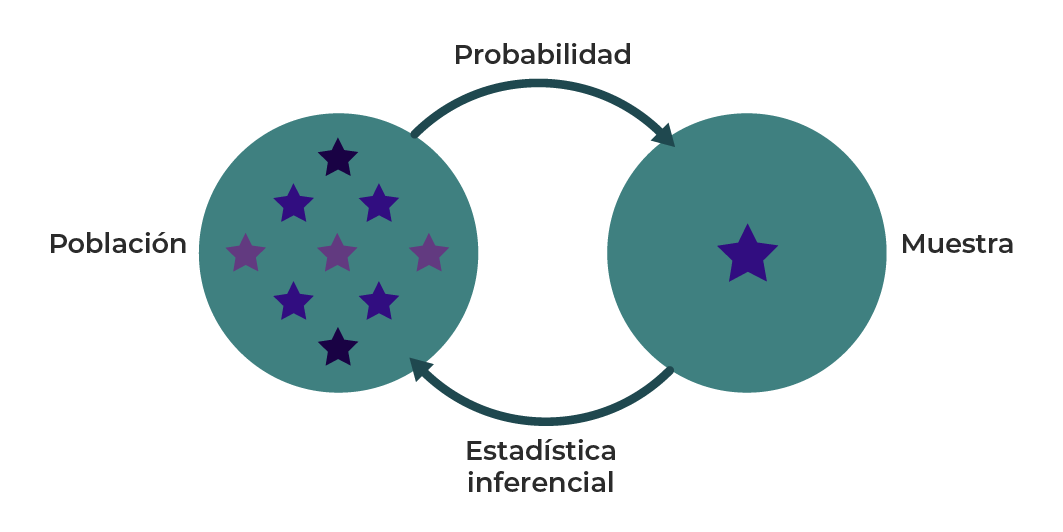
Diagrama 1. Probabilidad vs. estadística inferencial.
Se ha desarrollado la diferencia entre probabilidad y estadística mediante ejemplos. Describiendo que la estadística se divide en descriptiva e inferencial, considerando que la descriptiva se enfoca en resumir datos con medidas, como la media y la desviación estándar, mientras que la inferencial se enfoca en hacer suposiciones para inferir el contenido general de toda la población. En resumen, la probabilidad utiliza razonamiento deductivo, mientras que la estadística inferencial utiliza razonamiento inductivo.
¿Por qué es importante la estadística?
Al regresar a la perspectiva de Gutman y Goldmeier (2021) se proponen dos ejemplos de la vida real para comprender definitivamente la labor de cada disciplina; los casinos en Las Vegas y las encuestas políticas, para probabilidad y para estadística, respectivamente. A continuación, se describen ambos ejemplos.

Cada vez que juegas un juego de casino estás sacando de su bolsa de canicas, compuesta de ganancias y pérdidas. Hay suficientes canicas ganadoras dentro de la bolsa del casino para mantenerte interesado en jugar. Los casinos entienden la variación; de hecho, la han comercializado a través de pagos y pérdidas optimizados para mantenerte entusiasmado dentro del juego. Sin embargo, a largo plazo, los casinos saben que ganarán dinero porque ellos crearon la bolsa de la que se extraen todas las canicas y saben exactamente lo que hay dentro, conociendo la probabilidad implícita de éxito a cada momento.
 A diferencia de un casino, en una elección, los políticos no saben qué hay realmente dentro de la bolsa entera hasta el día de las elecciones cuando se revelan todas las canicas (para este caso, los votos). Entonces, antes de las elecciones, los políticos y sus partidos solo tienen acceso a un pequeño conjunto de canicas aleatorias (llamadas encuestas) y pagan mucho dinero por ese acceso. Usando esa muestra, infieren los patrones dentro de la bolsa y ajustan sus campañas en consecuencia. Debido a que su información es incompleta (y porque a menudo introducen sesgos y errores), no siempre lo hacen bien. Pero cuando lo hacen, es la diferencia entre ganar una elección o no.
A diferencia de un casino, en una elección, los políticos no saben qué hay realmente dentro de la bolsa entera hasta el día de las elecciones cuando se revelan todas las canicas (para este caso, los votos). Entonces, antes de las elecciones, los políticos y sus partidos solo tienen acceso a un pequeño conjunto de canicas aleatorias (llamadas encuestas) y pagan mucho dinero por ese acceso. Usando esa muestra, infieren los patrones dentro de la bolsa y ajustan sus campañas en consecuencia. Debido a que su información es incompleta (y porque a menudo introducen sesgos y errores), no siempre lo hacen bien. Pero cuando lo hacen, es la diferencia entre ganar una elección o no.
Estadística, Data Analysis y Machine Learning
Gutman y Goldmeier (2021) señalan que el primer paso para convertirse en un experto del análisis de datos (data analysis) es ayudar a una organización a trabajar en aquellos problemas de datos que importan, ya que han existido casos en los que las empresas sobrevaloran ciertos datos, malinterpretando los resultados o invirtiendo en tecnologías que no agregan valor comercial.
A menudo parece que los proyectos de datos se llevan a cabo porque las empresas se dejan llevar por la tecnología que está de moda sin comprender completamente por qué el proyecto en sí es importante. Esto conduce a la pérdida de tiempo y dinero, dando lugar a una probable reacción negativa contra futuros proyectos de datos. De hecho, en su afán por encontrar el valor oculto en los datos que muchas empresas esperan, a menudo fallan en el primer paso del proceso: definir el problema del negocio.
Además, Gutman y Goldmeier (2021) mencionan que cada empresa tiene una cultura única y, por eso, definir el problema del negocio mediante preguntas puede resultar efectivo. Y aunque no existe una fórmula única para todas las empresas y analistas de datos, simplemente hacer la pregunta correcta transformará el escenario de trabajo inicial.
De acuerdo con Gutman y Goldmeier (2021), la pregunta fundamental al comenzar es: “¿por qué es importante este problema?”. Aunque parece simple es algo que a menudo se pasa por alto, estancándose en la exageración de cómo se resolverá el problema del negocio, especulando qué se puede hacer incluso antes de comenzar. Entonces como mínimo, tal pregunta establece las expectativas del porqué se debe emprender el proyecto. Esto es importante ya que los proyectos de datos requieren tiempo, atención y, a menudo, inversiones adicionales en tecnología y datos. El simple hecho de identificar la importancia del problema desde antes ayudará a optimizar la forma en que se utilizan los recursos de la empresa.
Durante las discusiones iniciales es necesario mantener el enfoque en el problema del negocio central y no dejarse llevar por rumores sobre tendencias tecnológicas recientes. Hablar de estas puede desviar, rápidamente, la reunión del enfoque al negocio.

En la tabla 1 se ejemplifican los principales errores de enfoque.

Tabla 1. Principales errores del enfoque en el problema del negocio.
En la tabla anterior es posible notar que ambos errores involucran tecnología y aunque en algún punto del proyecto, tanto las metodologías como los entregables entran en escena, al inicio el problema debe expresarse en un lenguaje directo y claro que todos puedan entender, por eso lo recomendable es eliminar la terminología técnica y la retórica de marketing, comenzando con el problema en sí a resolver y no con la tecnología a utilizar.
Es así como Gutman y Goldmeier (2021) recomiendan a los equipos responder fundamentalmente la cuestión: "¿es este un problema, del negocio, real y que vale la pena resolver o solo se está haciendo ciencia de datos sin un sentido comercial?".
Por su parte, Sakhare et al. (2023) definen la ciencia de datos como una combinación de distintos campos, que utiliza estadística e Inteligencia Artificial (Machine Learning en específico) para la extracción de conocimiento a partir de la información recabada. Los datos pueden ser estructurados y no estructurados.
Lo anterior se ilustra en el diagrama 2.

Tabla 1. Principales errores del enfoque en el problema del negocio.
Muchas empresas fallan al sobrevalorar ciertos datos o invertir en tecnologías que no agregan valor comercial. Por tal razón se ha explicado la importancia de definir el problema del negocio y hacer la pregunta correcta para establecer las expectativas y optimizar el uso de los recursos, manteniendo el enfoque en el problema central y no dejarse llevar por rumores sobre tendencias o modas tecnológicas.


Ahora que comprendes más a fondo los conceptos de probabilidad y estadística, y como estos se relacionan con el análisis de datos, cuando dispongas de información o datos de algún tipo, convendría preguntarte: ¿es posible aplicar probabilidad o estadística a este problema?
Además, ahora conoces la importancia de definir el problema del negocio antes de decidir qué tipo de tecnología debes implementar.
Finalmente, al haber estudiado el concepto de Ciencia de datos es posible comprender que el Aprendizaje automático (Machine Learning) forma parte de este, mientras que la probabilidad y la estadística son la base de ambos.

Asegúrate de:
- Determinar la principal diferencia entre la probabilidad y la estadística para la correcta aplicación de los términos.
- Comprender la importancia de la estadística en el mundo actual con el propósito de comprender sus usos y casos de aplicación.
- Describir la relación entre la estadística, el Data Analysis y el Machine Learning para comprender la correcta aplicación de los términos y tecnologías inherentes.

- Devore, J. (2019). Fundamentos de probabilidad y estadística. México: Cengage.
- Gutman, A., y Goldmeier, J. (2021). Becoming a Data Head: How to Think, Speak, and Understand Data Science, Statistics, and Machine Learning. Estados Unidos: John Wiley & Sons.
- Sakhare, P., Chavan, P., Kulkarni, P., y Sarode, A. (2023). Instigation and Development of Data Science. Chavan, P., Mahalle, P., Mangrulkar, R., y Williams, I. (Eds.). Data Science: Techniques and Intelligent Applications. Estados Unidos: CRC Press.

Los siguientes enlaces son externos a la Universidad Tecmilenio, al acceder a ellos considera que debes apegarte a sus términos y condiciones.
Lecturas
Para conocer más acerca de introducción a la estadística para Data Analysis, te sugerimos revisar lo siguiente:
- Oracle. (s.f.). ¿Qué es la ciencia de datos? Recuperado de https://www.oracle.com/mx/what-is-data-science/
Videos
Para conocer más acerca de Texto, te sugerimos revisar lo siguiente:
- Datalitica. (2020, 29 de septiembre). ¿Cómo analizar los datos? [Archivo del video].Recuperado de https://youtu.be/80cRW6KIfk4

- Computadora con acceso a Internet.

- Deberás revisar el tema introducción a la estadística para Data Analysis.
