
 De acuerdo con Gutman y Goldmeier (2021), los datos sin procesar, con patrones implícitos, son la materia prima a partir de la cual se calcula la estadística, se crean modelos de aprendizaje automático (Machine Learning) o se realizan visualizaciones de paneles. Estos pueden ser datos almacenados en hojas de cálculo o bases de datos.
De acuerdo con Gutman y Goldmeier (2021), los datos sin procesar, con patrones implícitos, son la materia prima a partir de la cual se calcula la estadística, se crean modelos de aprendizaje automático (Machine Learning) o se realizan visualizaciones de paneles. Estos pueden ser datos almacenados en hojas de cálculo o bases de datos.
No obstante, si los datos aun no procesados son malos, ninguna cantidad de métodos de tratamiento de datos, de estadística o de aprendizaje automático podrá arreglarlos. Gutman y Goldmeier (2021), indican que es posible resumir tal situación con una frase: "basura que entra, basura que sale". A continuación, se presentan los tipos de preguntas que debes hacer para averiguar si tus datos sirven o no:
Conocer la historia del origen de los datos:
- ¿Quién recolectó los datos?
- ¿Cómo se recolectaron los datos?
¿Son representativos los datos?
- ¿Hay sesgo de muestreo?
En esta experiencia aprenderás a responder parte de las cuestiones anteriores, al saber cómo recolectar y organizar los datos, identificar lo que se conoce como sesgos cognitivos, entre otras herramientas esenciales de la estadística descriptiva.

Recolección y organización de datos
Al comenzar a trabajar con datos, desde la perspectiva de ciencia de datos, Gutman y Goldmeier (2021), recomiendan hacerlo con la pregunta: "¿cuál es el origen de estos datos?". Responder a esta pregunta no requiere conocimientos matemáticos o estadísticos. Además, genera confianza (o crea dudas) en los resultados de las etapas posteriores.
Después, analiza con atención la respuesta en busca de posibles problemas de corrección e integridad derivados de la persona u organización que creó los datos. Enfocándose en contestar preguntas como: ¿quién recolectó los datos? Al preguntar quién recolectó los datos, primero se busca establecer exactamente dónde se originaron los datos y segundo, si hay algún problema relacionado con su origen que conlleve a hacer un mayor seguimiento.

Muchas empresas grandes dan por sentado que sus datos fueron recolectados por un recurso interno. Por ejemplo, una empresa que utiliza datos de la fuerza laboral, es decir, datos basados en encuestas e información asociada de sus propios empleados, en realidad podría estar utilizando datos propios, recolectados por un proveedor externo. Esto último podría suceder a través de un portal de la empresa, dando la apariencia de que los datos fueron recolectados y son propiedad de esta, incluso cuando no lo son.
 En particular, Gutman y Goldmeier (2021), recomiendan identificar exactamente quién recolectó los datos, preguntándose si los datos externos son confiables y se relacionan con el problema del negocio de interés. En su mayoría los datos de terceros no se pueden usar fácilmente en el formato que se otorga a las empresas. Tú, o alguien del equipo de datos, será responsable de transformar los datos de un tercero en la estructura y el formato adecuados para alinearse con los activos de datos únicos de su empresa.
En particular, Gutman y Goldmeier (2021), recomiendan identificar exactamente quién recolectó los datos, preguntándose si los datos externos son confiables y se relacionan con el problema del negocio de interés. En su mayoría los datos de terceros no se pueden usar fácilmente en el formato que se otorga a las empresas. Tú, o alguien del equipo de datos, será responsable de transformar los datos de un tercero en la estructura y el formato adecuados para alinearse con los activos de datos únicos de su empresa.
¿Cómo se recolectaron los datos? De acuerdo con Gutman y Goldmeier (2021), también debes investigar cómo se recolectaron los datos. Esta pregunta ayudará a descubrir si se están sacando conclusiones sobre datos que no están permitidos. También le presentará si hay problemas éticos relacionados a la recolección de datos.

Existen dos métodos básicos de recolección de datos: observacionales y experimentales.
Los datos observacionales se recopilan de forma pasiva. Por ejemplo: las visitas de un sitio web, la asistencia a clases o las cifras de ventas.
Los datos experimentales se recopilan en condiciones experimentales con grupos de tratamiento y precauciones comprobadas para mantener la integridad y evitar confusiones. Debido al cuidado que brinda el experimento para garantizar que los resultados sean confiables, estos datos presentan una oportunidad sobre la cual obtener una comprensión causal. Por ejemplo, los datos experimentales pueden ayudar a responder las siguientes preguntas: si se le suministra a un paciente un nuevo fármaco, ¿curará su enfermedad? o si se realiza un descuento del 15% a un producto, ¿las ventas aumentarán el próximo trimestre?
Aunque la mayoría de los datos comerciales son observacionales, no deberían usarse (al menos, no exclusivamente) para derivar relaciones causales. Debido a que los datos no se recolectaron con un cuidado específico hacia un diseño experimental, la utilidad de los datos y sus resultados subyacentes deben presentarse dentro de tal contexto. Por lo tanto, Gutman y Goldmeier (2021), recomiendan recibir con escepticismo cualquier afirmación de causalidad empleando datos observacionales.
Preguntar cómo se recolectaron los datos te ayudará a descubrir si se estableció causalidad cuando no era posible hacerlo. Gutman y Goldmeier (2021), explican que la asignación incorrecta de causalidad es un problema bastante común.

Lo anterior debe hacerte pensar que es mejor opción recolectar datos experimentales, pero eso no siempre es posible, rentable o incluso ético. Por ejemplo, si se te asignó estudiar el impacto del "vapeo" (fumar cigarrillos electrónicos) en los adolescentes, no es posible asignar aleatoriamente a los adolescentes a un grupo de tratamiento y obligar al grupo a vapear en nombre de la ciencia. Eso no sería un tanto ético.
Como analista de datos debes trabajar con los datos que tienes y al mismo tiempo aprovecharlos para impulsar decisiones respecto al negocio. Algunas empresas y departamentos tienen los recursos para hacer el seguimiento de datos observacionales prometedores con experimentos sólidos. Sin embargo, otros problemas empresariales no se prestan fácilmente a los experimentos.
Por su parte Devore (2019), menciona que la estadística, además de abordar la organización y el análisis de datos una vez recolectados, también trabaja con el desarrollo de técnicas de recolección de datos. Explica que cuando la tarea implica seleccionar individuos u objetos de un conjunto, la forma más fácil de garantizar que la selección de una muestra sea representativa es mediante la utilización del método de muestreo aleatorio simple. Para esto puede usarse algún software generador de números aleatorios.

Devore (2019), indica que a veces se pueden usar otros métodos de muestreo, como el muestreo estratificado, para obtener información adicional o aumentar la confianza en las conclusiones. Este método implica dividir la población en grupos no superpuestos y tomar una muestra de cada grupo. Por ejemplo, un productor de botanas podría usar el muestreo estratificado para obtener información sobre la satisfacción del cliente para cada tipo de botana que producen. Esto garantizaría que cada tipo esté representado en la muestra y que ninguno esté sobrerrepresentado o subrepresentado.
Sakhare et al. (2023), recomiendan asegurarse de que haya suficiente calidad de datos y un acceso adecuado a estos para su uso posterior. Los datos pueden estar en varias formas, desde un archivo de Excel hasta diferentes tipos de bases de datos. En el diagrama 1 se muestra el proceso de recolección de datos.
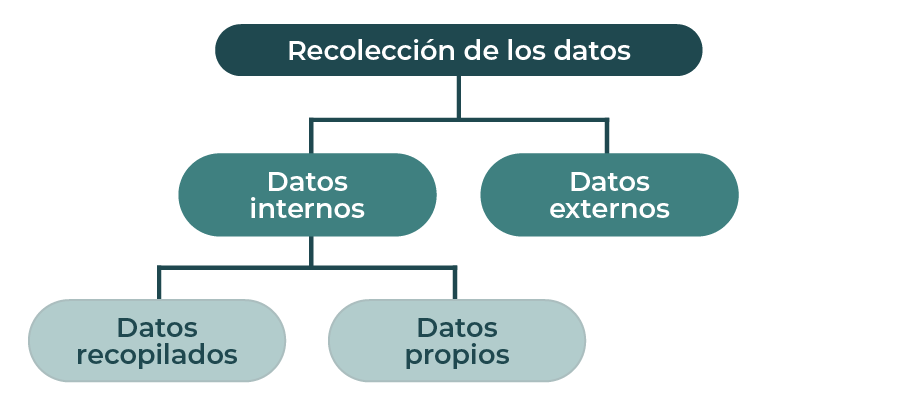
Diagrama 1. Proceso de recolección de datos.
Se ha explicado la importancia de conocer el origen y la forma en que se recolectaron los datos al iniciar a trabajar con ellos en el proceso de ciencia de datos. Además, se explicaron los dos métodos básicos de recolección de datos: observacionales y experimentales. A su vez, el método de muestreo aleatorio simple se utiliza para garantizar que la selección de una muestra sea representativa, pero a veces se pueden usar otros métodos, como el muestreo estratificado para aumentar la confianza en las conclusiones.
Sesgos cognitivos

Gutman y Goldmeier (2021), comentan que debes asegurarte de que los datos que tienes sean representativos del universo que te interesa. Por ejemplo, si te interesan los hábitos de compra de los adolescentes en México, el conjunto de datos que tiene debe ser representativo del universo más amplio de todos los hábitos de compra de los adolescentes de dicho país.
La estadística inferencial existe precisamente porque rara vez, o nunca, se tienen todos los datos que se requieren para resolver el problema. Esto conlleva a depender de muestras, pero si la muestra no es representativa, cualquier característica que se obtenga de la muestra no reflejará la realidad del universo.
Gutman y Goldmeier (2021) sugieren una pregunta específica para saber si tus datos son representativos: ¿hay sesgo de muestreo? Y en este punto es importante definir lo que se conoce como sesgo de muestreo. Este ocurre cuando los datos que tienes se encuentran constantemente fuera de lugar o son diferentes de aquellos que te interesan. El sesgo a menudo se descubre indirectamente después de que se han tomado muchas decisiones sobre datos que son poco representativos del problema. Solo después de que tales decisiones fallan continuamente en cuanto a predicción, los analistas regresan y revisan si los datos eran correctos en un principio.
Por ejemplo, si deseas conocer el índice de aprobación de un político y solo se encuestan a los votantes de su partido político, se ha introducido un sesgo de muestreo en los datos. Un buen diseño experimental maneja el potencial de sesgo de muestreo.
En el día a día es probable enfrentarse a datos inherentemente sesgados. Los datos de observación, en particular, son susceptibles de sesgo. Se recomiendan tratar todos los datos observacionales como inherentemente sesgados, sin la necesidad de descartarlos, pero trabajarlos dentro del contexto de sus deficiencias.
Data Wrangling
Sakhare et al. (2023), explican que en la etapa de preparación de datos se busca mejorar la calidad de los datos para su posterior procesamiento. A su vez, esta se divide en tres subetapas: limpieza, integración y transformación de los datos como se muestra en el diagrama 2.
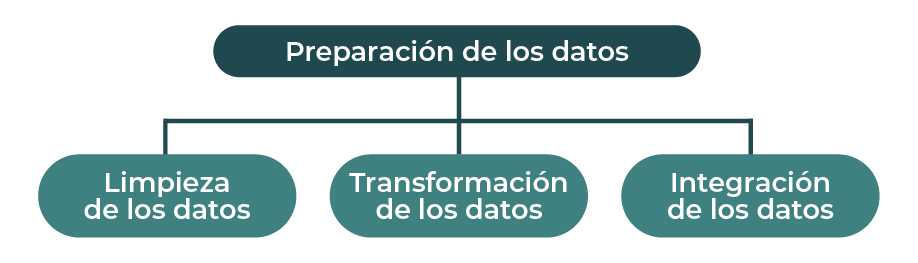
Diagrama 2. Preparación de los datos.

Por ejemplo, considera el siguiente modelo a ajustar:
![]()
donde la variable Y representa la distribución de energía eléctrica de una subestación y depende de dos variables continuas, X1 y X2, también se considera la variable de tipo de aerogenerador, con dos categorías: aerogenerador A y aerogenerador B. Para incorporar esta variable en el modelo, se sugiere agregar una variable ficticia Z con un coeficiente de regresión gamma, lo que resultaría en la aparición de un término adicional en el modelo:
![]()
Así la variable Z puede tener dos valores:
- Z = 0 si la observación se obtuvo del aerogenerador A.
- Z = 1 si la observación se obtuvo del aerogenerador B.
Clean
Como se comentó anteriormente, la limpieza de datos es un subproceso de la etapa de preparación de datos en la Ciencia de datos, que se centra en eliminar los errores de los datos para que se conviertan en una representación fiel y coherente del proceso del que se originaron.
Los errores se generan en dos tipos: de interpretación y de inconsistencia. El error de interpretación ocurre cuando se da por sentado el valor de los datos, mientras que el error de inconsistencia ocurre cuando hay muchas inconsistencias entre las fuentes de datos.
Sakhare et al. (2023), señalan que es posible detectar diferentes tipos de errores mediante un método de comprobación sencillo. La tabla 1 representa la descripción general de los errores que se detectan comúnmente. Es necesario resolver el problema lo antes posible en la cadena de adquisición, o de lo contrario, debe arreglarse en el programa para evitar problemas durante su posterior ejecución.
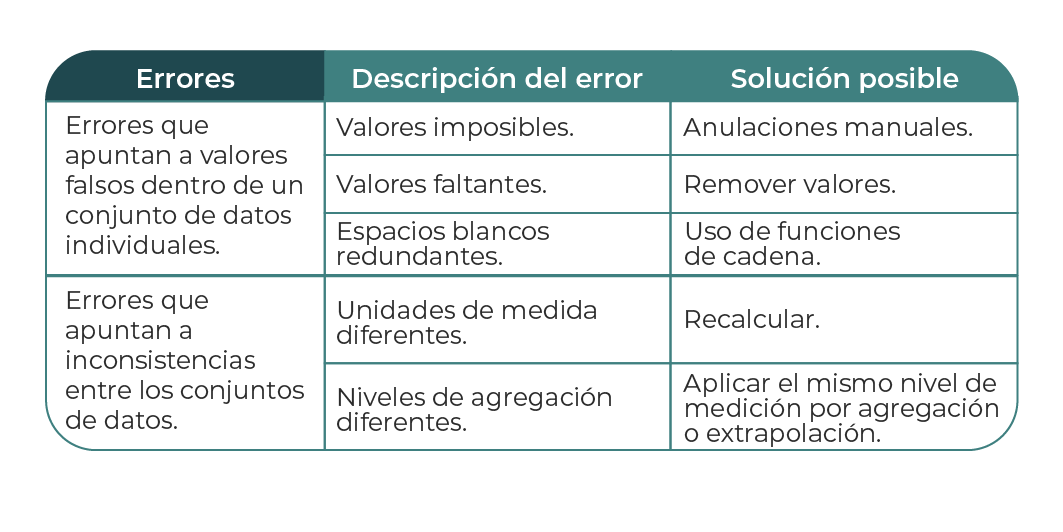
Tabla 1. Descripción de errores comunes.
En el siguiente ejemplo se muestra como antes de aplicar un aprendizaje automático (Machine Learning) a un conjunto de datos minoristas en línea ‘OnlineRetail.cvs’, representando una muestra en la tabla 2, es necesario realizar las siguientes tareas:
1. Cargar las bibliotecas necesarias para generar gráficos y emplear Machine Learning.
2. Cargar el conjunto de datos minoristas en línea (OnlineRetail.cvs).
3. Limpiar el conjunto de datos eliminando los valores NaN (Not a Number).

Tabla 2. Muestra de datos contenidos en conjunto de datos “minoristas en línea”.
El conjunto de datos contiene todas las transacciones que ocurren dentro de un cierto rango para un minorista en línea sin tienda registrada y con sede en el Reino Unido. La empresa vende principalmente regalos únicos para toda ocasión y varios clientes de la empresa son mayoristas.

En la tabla 3 se muestra el código en lenguaje Python para realizar las tres tareas mencionadas anteriormente. Como entorno de ejecución se emplea Google Colab, pues permite el uso de cualquier librería de Python sin necesidad de descargarla.

Tabla 3. Código en lenguaje Python para realizar la limpieza de los datos.
También es posible apreciar que, en la tabla 3, al ejecutar el código, a la salida se obtuvo el porcentaje de valores “NaN” en cada campo. Por ejemplo, para el caso de descripción solo existe un 0.27% de faltantes, mientras que para el caso de ID del cliente se tiene hasta un 24.93% de elementos vacíos. Así, al agrupar dicha información mediante la estructura de datos “df_null”, es posible realizar la discriminación o limpieza de los datos para procesarlos en etapas más avanzadas (exploración y modelado).
Histogramas
Un diagrama de frecuencia relativa en forma de histograma guarda similitud con una gráfica de barras, pero su utilidad radica en la representación de cantidades en lugar de datos cualitativos. Devore (2019), explica que, para calcular el valor de una variable, se pueden recoger datos numéricos de diferentes maneras, como contar el número de multas de tráfico que recibió una persona durante el año anterior o el número de personas que buscan empleo en un período determinado. Otros datos se miden, como el peso de una persona o el tiempo de respuesta a un estímulo en particular. Sin embargo, los procedimientos para crear un histograma difieren en estos dos casos.
 Para establecer el valor de una variable, se pueden obtener algunos datos numéricos contando y otros se pueden conseguir midiendo, como el peso de una persona o el tiempo que tarda en reaccionar a un estímulo particular. En general, la manera de crear un histograma puede variar dependiendo de si los datos se obtuvieron mediante conteo o medición.
Para establecer el valor de una variable, se pueden obtener algunos datos numéricos contando y otros se pueden conseguir midiendo, como el peso de una persona o el tiempo que tarda en reaccionar a un estímulo particular. En general, la manera de crear un histograma puede variar dependiendo de si los datos se obtuvieron mediante conteo o medición.
Una variable numérica es discreta si su conjunto de valores es contable o finito. En cambio, una variable es continua si es posible obtener infinitos valores para ésta en un intervalo sobre la recta numérica.
Una variable discreta X por lo general se obtiene de la acción de contar, por ejemplo, 0, 1, 2, 3, ..., o algún subconjunto de tales enteros. Por su parte, las variables continuas comúnmente surgen al realizar mediciones, por ejemplo, si X es la corriente en un circuito electrónico, en teoría X podría ser cualquier número entre 5 y 20 mA: 6.5, 7.12, 10.06, y así sucesivamente.
Es importante tener en cuenta que, en la vida real, los instrumentos de medición tienen limitaciones en cuanto a su precisión, por lo que puede que no sea posible obtener un valor con una gran resolución. Sin embargo, al tratar de crear modelos matemáticos para las distribuciones de datos, es útil imaginar un conjunto continuo de valores posibles. Al considerar los datos compuestos por las observaciones de una variable discreta X, la frecuencia de un valor particular X se refiere al número de veces que aparece ese valor en el conjunto de datos. Por otro lado, la frecuencia relativa de un valor se refiere a la fracción o proporción de veces que aparece en los datos:
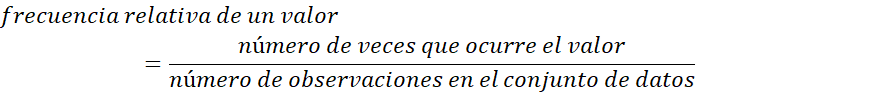

Por ejemplo, si el conjunto de datos se compone de 100 observaciones de X, el número de veces que un ciudadano va al médico al año. Si 50 de estos valores X son 3, entonces:
Frecuencia del valor x=3:50
Frecuencia relativa del valor x=3:![]()
Cuando se multiplica la frecuencia relativa por 100 se obtiene un porcentaje; en el ejemplo anterior, 50% de los ciudadanos de la muestra van tres veces al médico al año. En general, la atención se centra más en las frecuencias relativas o porcentajes que en las frecuencias absolutas. Una tabla que presenta las frecuencias o las frecuencias relativas, o ambas, se conoce como distribución de frecuencias.
Construcción de un histograma para datos discretos. Devore (2019), recomienda que, en primer lugar, se determinen la frecuencia y la frecuencia relativa de cada valor X. Luego se marcan los valores x posibles en una escala horizontal. Sobre cada valor se traza un rectángulo cuya altura es la frecuencia relativa (o alternativamente, la frecuencia) de dicho valor: los rectángulos deben medir lo mismo de ancho.

Se ha realizado el estudio del peso en toneladas de los tráileres que acceden durante una jornada a un parque industrial ubicado en una alcaldía con alta actividad comercial en CDMX, epicentro de operaciones logísticas para pequeñas y medianas empresas, importadoras y exportadoras. Del estudio se registró la información de 350 camiones, como se muestra en la tabla 4.
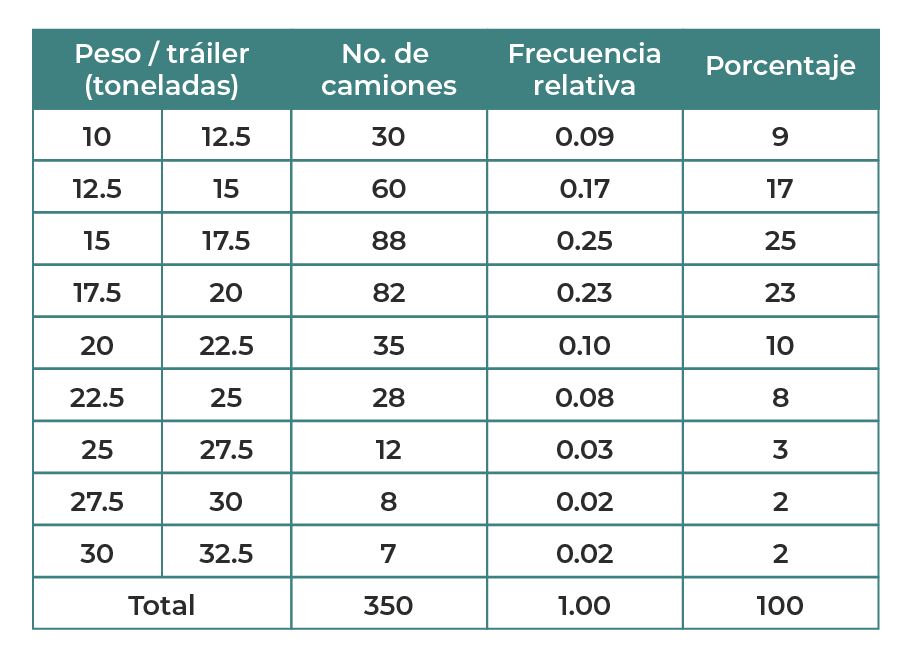
Tabla 4. Distribución de frecuencia de tráileres por peso.
Al emplear los datos de la tabla 4, se obtiene el histograma de la gráfica 1.
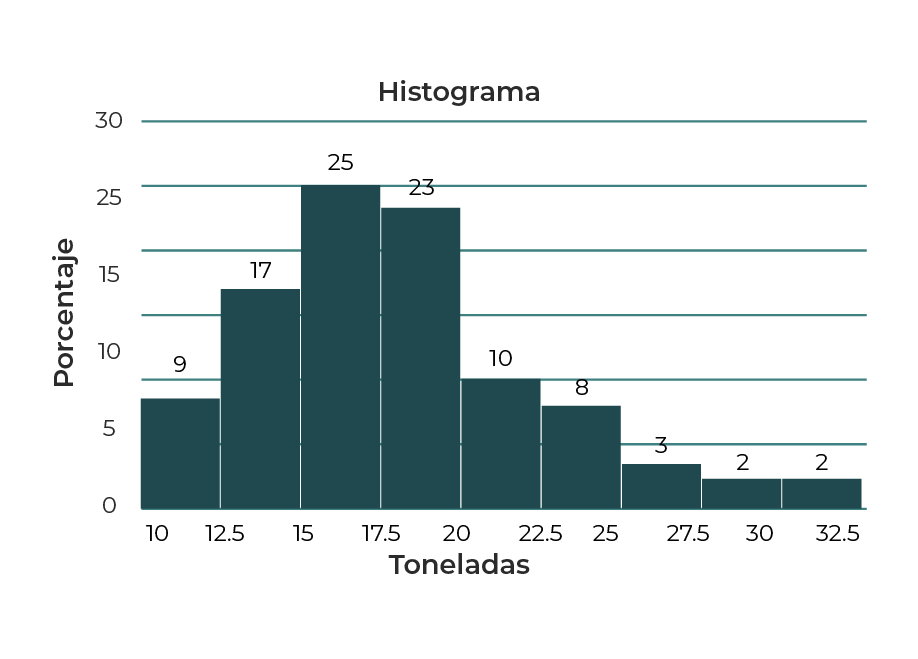
Gráfica 1. Histograma de porcentaje de tráileres por peso.
Tanto la tabla de datos como el histograma permiten realizar el siguiente análisis:
Porcentaje de camiones = 25% + 23% = 48% entre 15 y 20 toneladas.
Devore (2019), también señala que crear un histograma para datos continuos implica dividir el eje de medición en un número apropiado de categorías o intervalos de clase, de tal manera que cada medición se encuentre exactamente en una categoría.
De este modo, es posible apreciar la importancia del uso de histogramas para el estudio y análisis de cualquier conjunto de datos cualitativos, representando una herramienta para: la toma de decisiones, comprobación de la normalización de los datos, entre otras.
Distribuciones normales y uniformes
La distribución normal es fundamental tanto en probabilidad como en estadística. Muchas poblaciones numéricas muestran una distribución que puede ser representada con precisión mediante una curva normal adecuada. Algunos ejemplos incluyen características físicas como la estatura y el peso, errores en experimentos científicos, mediciones en fósiles antropométricos, tiempos de reacción en experimentos psicológicos, resultados en pruebas de inteligencia y aptitud, calificaciones en exámenes, y muchos indicadores económicos. Además, aunque las variables individuales no siempre tienen una distribución normal, las sumas y promedios de estas variables, bajo ciertas condiciones, tendrán una distribución aproximadamente normal.
Devore (2019), explica que la función de probabilidad para una variable aleatoria continua X con parámetros ![]() ,
, ![]() , y
, y ![]() considerando
considerando ![]() y
y ![]() , se describe matemáticamente de la siguiente manera:
, se describe matemáticamente de la siguiente manera:
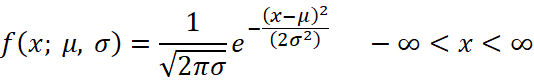
Bajo el contexto matemático, “e” se refiere a la base del sistema de logaritmos naturales con un valor cercano a 2.718, mientras que “π” es la conocida constante con un valor aproximado de 3.1416. En la próxima sección se explicarán la media poblacional (μ) y la desviación estándar poblacional (σ).
Favor de hacer un cierre de subtema luego de las correcciones, en caso de que se agregue información al subtema, debe reflejarse aquí.

En el siguiente ejemplo se ha generado un conjunto de datos empleando la función de distribución normal y software para ![]() y
y ![]() , donde
, donde ![]() , estos se muestran en la tabla 5.
, estos se muestran en la tabla 5.

Tabla 5. Distribución normal de datos para 1 < x <7.
Al utilizar el mismo software es posible obtener la gráfica 2, donde se puede apreciar que la mayor área bajo la curva se encuentra en el valor de la media y conforme se recorre la desviación estándar por unidad hacia la izquierda o derecha, el área bajo la curva disminuye.
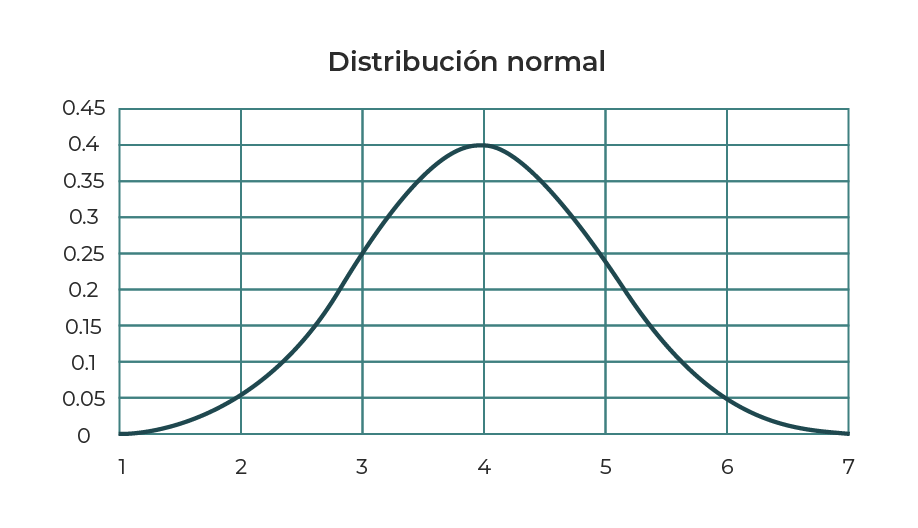
Gráfica 2. Curva de distribución normal para conjunto de datos.
Cuando a la distribución normal se le asignan como valores de parámetro ![]() y
y ![]() se le conoce como distribución normal estándar.
se le conoce como distribución normal estándar.
Definiciones de moda, promedio (media aritmética) y varianza
Las gráficas pueden ser útiles para describir una distribución de datos, pero tienen limitaciones, como la imposibilidad de verlas sin una pantalla o describirlas por teléfono. Además, también pueden resultar imprecisas para hacer inferencias estadísticas. Por esta razón, es recomendable utilizar medidas numéricas para tener una imagen más clara de la distribución de frecuencia. Estas medidas se llaman parámetros cuando se relacionan con la población y estadísticas cuando se calculan a partir de una muestra.
Moda. En el ámbito de la estadística, se utiliza el término moda para referirse al valor que aparece con mayor frecuencia en un conjunto de datos. Por ejemplo, si se tiene el siguiente conjunto de datos:
X = {9, 10, 7, 39, 40, 18, 11, 22, 19, 2, 3, 39, 5, 6}, la moda es 39.
Promedio (media aritmética). Para distinguir entre la media muestral o aritmética y la media de una población se emplea el símbolo ![]() para una y el símbolo
para una y el símbolo ![]() para la otra, respectivamente.
para la otra, respectivamente.
La definición matemática de la media aritmética o promedio ![]() de un conjunto de elementos
de un conjunto de elementos ![]() se expresa como:
se expresa como:
![]()

Se presenta la información de un total de 14 resistores proporcionada por un fabricante de componentes electrónicos. Se supone que el valor de todos los resistores debería corresponder exactamente a 220 ohms, pero debido a la naturaleza y propiedades del material existe una variación de +/- 3 ohms, como puede notarse a continuación:
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
La suma de todos los valores equivale a 3082.8 ohms, es decir ![]() ohms, por lo tanto, la media muestral se calcula del siguiente modo:
ohms, por lo tanto, la media muestral se calcula del siguiente modo:
![]() ohms
ohms
Una explicación física de la media muestral te presenta cómo se determina el valor central de una muestra. Por esta razón se puede ver como el punto de equilibrio de la distribución de los datos recopilados.
Varianza y desviación estándar. La variabilidad o dispersión es un aspecto crucial de los datos. Por ejemplo, si se quiere diferenciar entre abogados buenos y malos, pero en el examen diagnóstico siempre se producen calificaciones con poca variabilidad, esto haría difícil la discriminación. Entonces, las medidas de variabilidad como la varianza y la desviación estándar pueden ayudar para darse una idea sobre la dispersión de los datos.
Las medidas de variabilidad más importantes se basan en las desviaciones con respecto a la media, lo que implica restar el valor medio de ![]() de cada una de las n observaciones obtenidas en la muestra.
de cada una de las n observaciones obtenidas en la muestra.
Tomando en cuenta lo anterior, la varianza muestral, denotada por ![]() , se define como:
, se define como:
![]()
La desviación estándar muestral, que se representa como ![]() , se calcula a partir de la varianza como la raíz cuadrada (siempre positiva) de esta última.
, se calcula a partir de la varianza como la raíz cuadrada (siempre positiva) de esta última.
![]()
Puedes notar que tanto ![]() como
como ![]() no son negativas. Además, del mismo modo en que se diferencian la media muestral de la poblacional, la desviación estándar de una población se denota como
no son negativas. Además, del mismo modo en que se diferencian la media muestral de la poblacional, la desviación estándar de una población se denota como ![]() .
.

Se presenta la siguiente muestra de n = 15 alcaldías de una ciudad metropolitana donde se recolectó el precio de 1 kilogramo de tortillas.
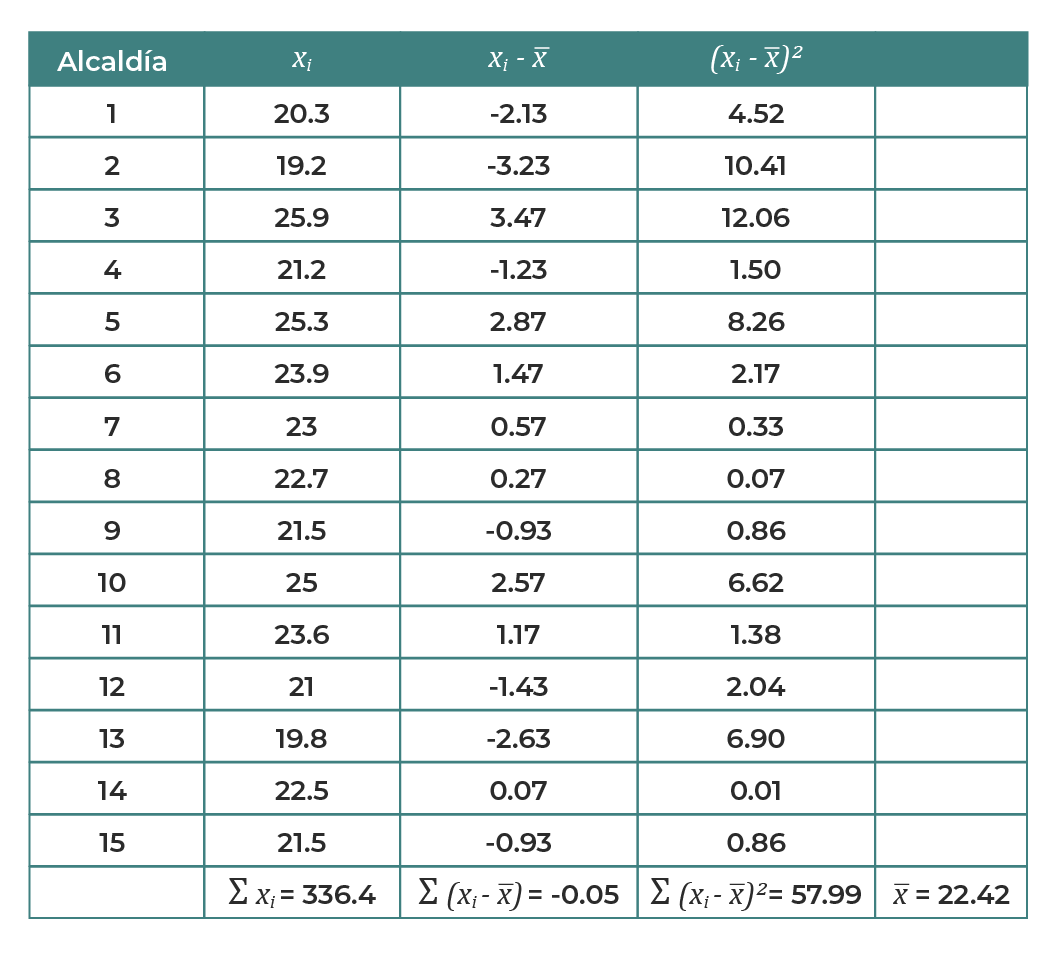
Tabla 6. Resumen de muestras del precio de tortilla por alcaldía.
Considerando los valores calculados en la tabla 6, se realiza el cálculo de la varianza y desviación estándar:
![]()
Así se demuestra que las representaciones gráficas como histogramas para propósitos específicos pueden resultar imprecisas para hacer inferencias estadísticas, pero una forma de superar este problema es utilizando medidas numéricas que permitan obtener una idea más clara de la distribución de frecuencias como lo son la moda, media aritmética, varianza y desviación estándar.


Después de haber estudiado el proceso para tratar los datos junto a conceptos como sesgo, serás capaz de comprender aquellos casos en los que un modelo no representa adecuadamente un problema.
Además, ahora sabes cuales son aquellas preguntas que un analista de datos junto a su equipo debe contestar con el propósito de definir el problema del negocio y saber si los datos recolectados servirán para crear la solución o no.
Finalmente, ahora que conoces el uso de herramientas de probabilidad y estadística, como la construcción de histogramas, así como el cálculo de la media, varianza y desviación estándar podrás aplicarlo a diferentes problemas, a la vez que eres capaz de interpretar sus resultados.

Asegúrate de:
- Describir las etapas en el proceso de recolección y organización de los datos para prepararlos y hacer ciencia de datos.
- Comprender el concepto de sesgo cognitivo en los datos para evitar errores en la construcción de modelos.
- Calcular los valores de moda, media, varianza y desviación estándar en el conjunto de muestras para analizar la variabilidad en los datos.

- Devore, J. (2019). Fundamentos de probabilidad y estadística. México: Cengage.
- Gutman, A., y Goldmeier, J. (2021). Becoming a Data Head: How to Think, Speak, and Understand Data Science, Statistics, and Machine Learning. Estados Unidos: John Wiley & Sons.
- Sakhare, P., Chavan, P., Kulkarni, P., y Sarode, A. (2023). Instigation and Development of Data Science. Chavan, P., Mahalle, P., Mangrulkar, R., y Williams, I. (Eds.). Data Science: Techniques and Intelligent Applications. Estados Unidos: CRC Press.

Los siguientes enlaces son externos a la Universidad Tecmilenio, al acceder a ellos considera que debes apegarte a sus términos y condiciones.
Lecturas
Para conocer más acerca de bases estadísticas, te sugerimos revisar lo siguiente:
- Pierre, N. (2021). Preparación de datos: definición, ejemplos, consejos [guía 2021]. Recuperado de https://www.intotheminds.com/blog/es/data-preparacion-datos/
Videos
Para conocer más acerca de bases estadísticas, te sugerimos revisar lo siguiente:
- CursoLaboral. (2020, 14 de marzo). Limpieza de datos - Analista de datos 10 [Archivo de video]. Recuperado de https://youtu.be/96JDnOFE56A

- Computadora con acceso a internet.

- Deberás revisar el tema bases estadísticas.
- Instalar Microsft Excel (cualquier versión).
- Google Colab (software público), solo es necesario crear una cuenta Gmail para su uso.
