
Cuando se habla sobre Machine Learning (aprendizaje automático) se piensa en programas inteligentes capaces de realizar cualquier cosa y aunque actualmente esto parece ser una realidad, en términos más formales, Rafatirad et al. (2022) explican que el Machine Learning es un subcampo de la Inteligencia Artificial (IA), la cual representa la colección de conceptos que permite a las computadoras imitar la inteligencia humana.
Los sistemas actuales utilizan modelos de aprendizaje automático para transformar datos en resultados procesables y llevar a cabo tareas específicas, como detectar actividad maliciosa, clasificación de objetos en vehículos autónomos o descubrir correlaciones interesantes entre variables en un conjunto de datos de prácticamente cualquier tipo. Los algoritmos de aprendizaje automático incluyen regresión, árboles de decisiones, agrupamiento, redes neuronales artificiales, aprendizaje profundo y muchos más.
En esta experiencia de aprendizaje conocerás la relación entre la probabilidad y el Machine Learning, así como uno de sus algoritmos más populares: las redes neuronales artificiales. Como último concepto se abordará el Big Data, presentando su funcionamiento con base en todo lo anterior.

Machine Learning
Rafatirad et al. (2022) explican que el objetivo principal del campo de la Inteligencia Artificial es desarrollar algoritmos artificiales que puedan usarse para informar juicios futuros inteligentes y el Machine Learning se ocupa de enseñar/entrenar a tales algoritmos para la ejecución de dichas tareas. Por lo tanto, el Machine Learning puede definirse como una técnica científica para descubrir patrones ocultos y conclusiones en datos estructurados y no estructurados mediante la construcción de modelos matemáticos, utilizando un conjunto de datos de muestra denominado conjunto de entrenamiento.
¿Qué es probabilidad y Machine Learning? Rafatirad et al. (2022), a su vez, señalan que el Machine Learning puede abordarse de dos maneras distintas: el teórico y el aplicado. Ambos caminos facultan a una persona para resolver problemas de formas diferentes. El Machine Learning teórico se ocupa de la comprensión de los conceptos fundamentales detrás de sus algoritmos: las matemáticas, las estadísticas y la teoría de la probabilidad.
Por otra parte, Rafatirad et al. (2022) mencionan que el Machine Learning aplicado consiste en lograr alcanzar el potencial y el impacto de los desarrollos teóricos del mismo. Así, su propósito es abordar problemas del mundo real utilizando herramientas y marcos que incorporan algoritmos basados en los principios de la teoría. Tiene que ver con el desarrollo de un sistema de aprendizaje viable para una aplicación particular. De hecho, la importancia del Machine Learning aplicado proviene de resolver numerosos problemas de forma secuencial en múltiples áreas, lo que requiere una comprensión de los datos y desafíos implicados. Esta no es una tarea fácil, ya que no existe ningún conjunto de datos o algoritmo que sea óptimo para todas las aplicaciones o situaciones.
 Muchas aplicaciones del mundo real tienen una naturaleza no determinista y un comportamiento variable, ya que no hay garantía de obtener siempre el mismo resultado para la misma entrada. Dado que las incertidumbres para el Machine Learning provienen de varios factores, como varios parámetros y entornos complejos, la teoría de la probabilidad juega un papel clave.
Muchas aplicaciones del mundo real tienen una naturaleza no determinista y un comportamiento variable, ya que no hay garantía de obtener siempre el mismo resultado para la misma entrada. Dado que las incertidumbres para el Machine Learning provienen de varios factores, como varios parámetros y entornos complejos, la teoría de la probabilidad juega un papel clave.
En varios algoritmos, la probabilidad es la base del Machine Learning, por ejemplo, se utiliza en tareas de clasificación para predecir la probabilidad de que un elemento pertenezca a cierta clase. Algunos algoritmos, como los árboles de decisiones, recurren a la probabilidad para seleccionar una ruta de acción adecuada; de hecho, unos cuantos, de ellos, como los de regresión logística y redes neuronales, basan su entrenamiento en entornos de probabilidad.
¿Qué son las redes neuronales? Rafatirad et al. (2022) comentan cómo muchos problemas del mundo real no se pueden clasificar en problemas lineales o en las técnicas de regresión no lineal. Entonces, a lo largo de la historia moderna de la computación se han desarrollado algoritmos como las redes neuronales artificiales (RNA) para hacer frente a los complejos desafíos de clasificación. Las RNA son representaciones básicas de un cerebro humano que replican el aprendizaje no lineal a través de una red de neuronas. Por tal razón, la neurona es el componente fundamental para las redes neuronales artificiales (RNA).

En el año 1943, McCulloch y Pitts propusieron por primera vez el modelo simplificado de una neurona biológica, popularmente conocido como modelo M-P, que ha sido ampliamente adoptado y mejorado en los últimos tiempos. El modelo M-P de la neurona se puede dividir en dos partes. En primer lugar, la neurona suma todas las señales entrantes y las agrega, como se muestra en el cuadro del lado derecho (capa de salida) del diagrama 1 y matemáticamente puede definirse de la siguiente manera:
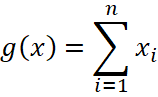
Donde ![]() representa la suma agregada de las entradas
representa la suma agregada de las entradas ![]() . Además, la suma agregada atraviesa la función de activación
. Además, la suma agregada atraviesa la función de activación ![]() , por lo que el modelo de una neurona se proporciona como
, por lo que el modelo de una neurona se proporciona como ![]() .
.
Con el tiempo, los modelos han mejorado, tales avances comprenden la inclusión del sesgo, la suma ponderada de las entradas y el trabajo con entradas ![]() no binarias.
no binarias.
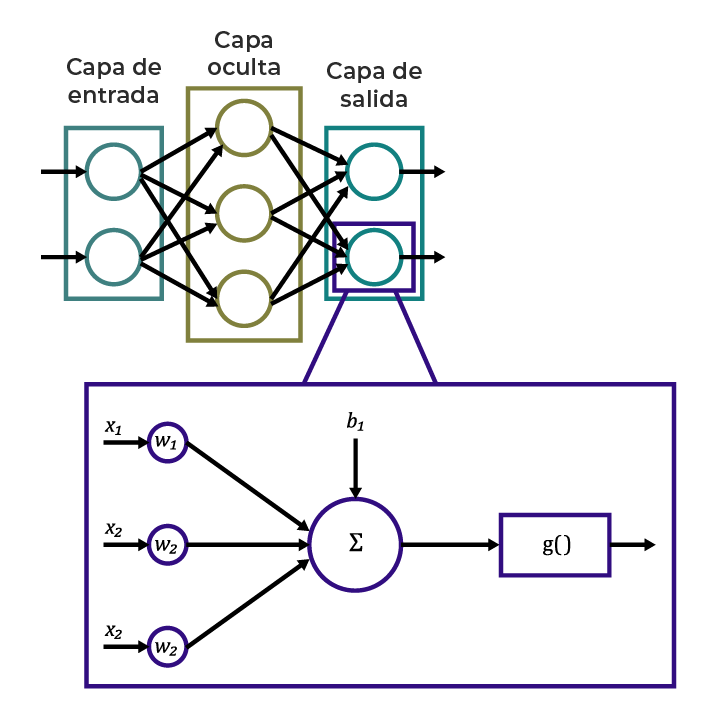
Diagrama 1. Red neuronal de una sola capa oculta con dos entradas y dos salidas.
Una neurona artificial agrega datos de entrada usando una función de combinación, y la salida de esta sirve para alimentar una función de activación (generalmente, una función no lineal como sigmoide, función de paso binario o softmax), produciendo una salida que se canaliza a las neuronas en otras capas de la red. El diagrama anterior muestra una red neuronal en la que cada neurona agrega las entradas que ingresan y escala la salida de la función de combinación (![]() ) utilizando una función de activación.
) utilizando una función de activación.
Uno de los requisitos de las RNA es estandarizar los atributos del conjunto de datos (categóricos o continuos) para que tomen un valor entre 0 y 1. Un ejemplo del uso de una variable indicadora para codificar un atributo categórico es representar un género masculino como 0 y un género femenino como 1.
Rafatirad et al. (2022) explican que, en una red neuronal, hay neuronas en la capa de entrada, la oculta y la de salida. La capa de entrada es aquella que recibe los atributos del conjunto de datos, y la de salida es la última capa de la red que produce el resultado del clasificador. Las capas entre la capa de entrada y la de salida se denominan capa oculta. El número de neuronas en estas capas no tiene que ser siempre el mismo. Este número puede cambiar caso por caso y dependiendo del problema. Por ejemplo, puedes tener un nodo de salida en una red neuronal o varios nodos de salida según el problema de clasificación. Para problemas de clasificación binaria, se usa una neurona en la capa de salida.

¿Qué es Big Data? En el contexto de la ciencia de datos, el término Big Data se emplea para aquellos datos que son más grandes que los tradicionales. Se trata de conjuntos de datos complejos que son difíciles de administrar con métodos tradicionales. Los grandes datos, generalmente, se distribuyen a través de una gran red que cambia según la variedad (números, texto, audio, video), la velocidad y el volumen (tera, peta o exabytes). Ver el diagrama 2.
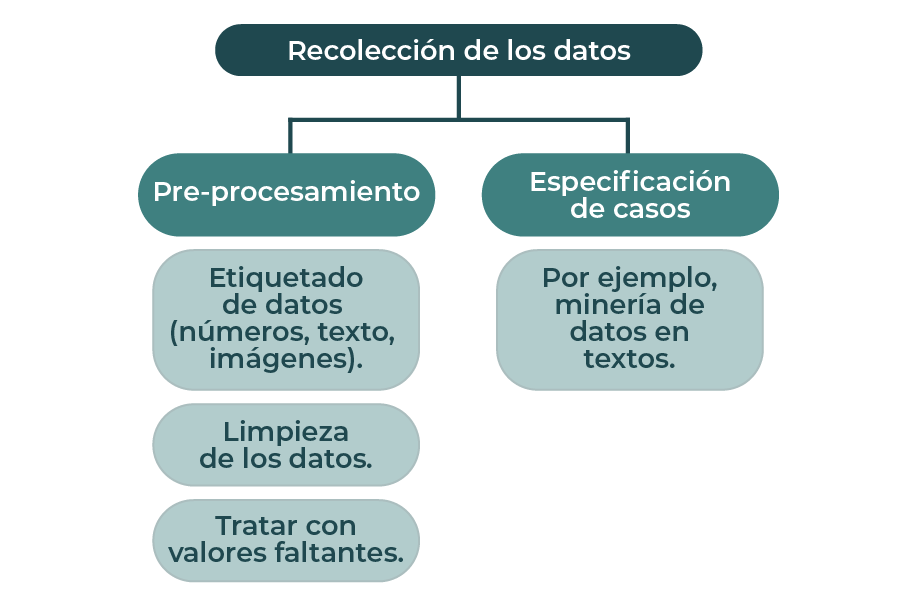
Diagrama 2. Proceso de Big Data.
En Big Data, como la complejidad de los datos es muy grande, la etapa de preprocesamiento se vuelve crucial. Algunas de las etapas del Big Data son bastante similares al método usado para datos tradicionales. A continuación, se enlistan las etapas de preprocesamiento en Big Data:
- Recolección de los datos.
- Etiquetado de clases.
- Limpieza de los datos.
- Enmascaramiento de datos.
Se ha explicado que el enfoque teórico se centra en comprender los conceptos fundamentales detrás de los algoritmos de Machine Learning, como las matemáticas, las estadísticas y la teoría de la probabilidad, que es la base de varios algoritmos de clasificación. Sin embargo, los problemas del mundo real a menudo son no lineales, lo que ha llevado al desarrollo de algoritmos más avanzados como las redes neuronales artificiales (RNA), que replican el aprendizaje no lineal a través de una red de neuronas. Además, se ha abordado el término Big Data, que se refiere a conjuntos de datos más grandes y complejos que son difíciles de administrar con métodos tradicionales debido a su variedad, velocidad y volumen distribuidos a través de una gran red.
Extracción de conclusiones
Rafatirad et al. (2022) explican que, en ciencia de datos, el término "ciencia" hace referencia al conocimiento que se obtiene a través de un estudio sistemático sobre los datos. Básicamente, es un plan sistemático que construye y organiza el conocimiento en una forma que es fácilmente comprobable en explicaciones y predicciones.
Por su parte, Sakhare et al. (2023) señalan que la ciencia de datos y el Machine Learning (ML) están relacionados entre sí, pero tienen objetivos y funcionalidades diferentes. El ML es una parte crítica de la ciencia de datos donde utiliza de manera efectiva diferentes algoritmos estadísticos para analizar los datos de múltiples recursos.

El ML está vinculado principalmente a la etapa de modelado de datos, aunque también se puede utilizar en la mayoría de las etapas del proceso de ciencia de datos (ver el diagrama 3). La fase de modelado de datos no puede comenzar hasta que se comprendan los datos crudos cualitativos. Pero antes de eso, la fase de preparación de datos tiene beneficios significativos a través del ML. Por ejemplo, en la limpieza de cadenas de texto, el ML ayuda a agrupar las mismas cadenas para que sea más fácil corregir errores ortográficos.
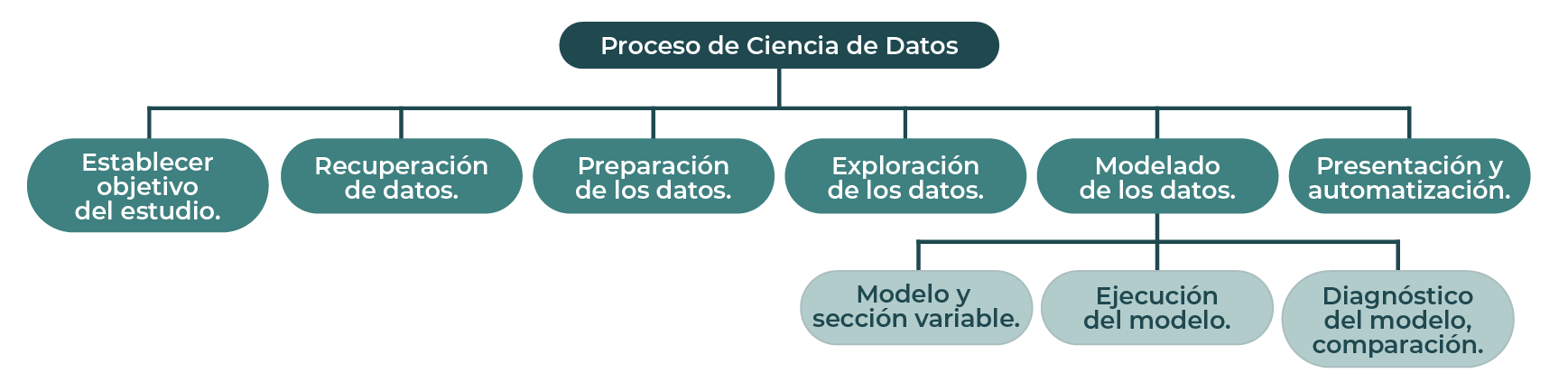
Diagrama 3. Machine Learning usado en el proceso de ciencia de datos.
El Machine Learning también es útil para explorar los datos. Los algoritmos pueden reconocer los patrones implícitos en los datos y se representan a través de varias herramientas de visualización que incluyen gráficos de distintos tipos.
Los científicos de datos deben conocer los principales algoritmos de ML, pues estos se utilizan ampliamente en el procesamiento de los datos. A continuación, se describen tales algoritmos:
- Regresión lineal. El algoritmo de regresión lineal se utiliza principalmente con fines de predicción y previsión. La regresión es el método de modelado de los valores objetivo que se basa en variables independientes. Ayuda a representar la ecuación lineal, que tiene la conexión entre el conjunto de entrada y la salida predictiva. Dado que determina la relación lineal entre las variables de entrada/salida, se conoce como regresión lineal.
- Árboles de decisión. Este algoritmo de aprendizaje automático es ampliamente conocido porque puede usarse tanto en problemas de clasificación como de regresión. En el algoritmo del árbol de decisión, puedes resolver el problema usando una representación de árbol en la que cada nodo representa características, cada rama muestra una decisión y cada hoja representa los resultados.
- Agrupamiento k-medias. A diferencia de los algoritmos anteriores que pertenecen al aprendizaje supervisado, el agrupamiento en k-medias funciona con aprendizaje no supervisado. Resuelve los problemas relacionados con el agrupamiento de los datos en conjuntos de acuerdo con patrones o características. A cada conjunto de datos se le conoce como clústeres. El objetivo principal de este algoritmo es alcanzar la máxima similitud en los datos dentro de un clúster.
Los algoritmos de ML tienen una amplia gama de aplicaciones en la ciencia de datos, algunos de los dominios de aplicación se enumeran a continuación:
- Educación.
- Industria financiera.
- Segmentación de clientes.
- Mecanismo de predicción de enfermedades.
- Predicción de precios.
En cada una de esas aplicaciones se realiza el proceso de ciencia de datos descrito anteriormente y de acuerdo con la naturaleza de cada problema campo, se realiza a su vez la extracción de conclusiones a partir del análisis de datos, permitiendo la construcción de la solución.


Ahora que comprendes más a fondo los conceptos de Machine Learning y Ciencia de Datos, además del cómo estos permiten la línea de un proceso donde los datos pueden procesarse hasta obtener modelos que permitan predecir o categorizar, probablemente vale la pena preguntarse ¿a qué tipo de problemas resulta posible aplicar tales técnicas?
Además, ahora conoces el concepto de Big Data y su relevancia en el mundo actual, por lo que puedes profundizar en aquellos elementos que lo conforman y especializarte en algún campo aplicado a esta tecnología.
Finalmente, al haber estudiado el camino de implementación de la ciencia de datos pudiste notar que el uso de los principales algoritmos de Machine Learning hace posible el proceso de extracción de conclusiones en diferentes campos dando como resultado múltiples aplicaciones.

Asegúrate de:
- Describir la relación entre Machine Learning y probabilidad con el propósito de utilizar ambos conceptos como herramientas que impulsan al Big Data.
- Comprender el concepto de Big Data para valorar su importancia en la actualidad.
- Enumerar los principales algoritmos de Machine Learning aplicados en ciencia de datos para analizar su propósito y aplicación.

- Rafatirad, S., Homayoun, H., Chen, Z., y Dinakarrao, S. (2022). Machine Learning for Computer Scientists and Data Analysts From an Applied Perspective. Estados Unidos: Springer.
- Sakhare, P., Chavan, P., Kulkarni, P., y Sarode, A. (2023). Instigation and Development of Data Science. Chavan, P., Mahalle, P., Mangrulkar, R., y Williams, I. (Eds.). Data Science: Techniques and Intelligent Applications. Estados Unidos: CRC Press.

Los siguientes enlaces son externos a la Universidad Tecmilenio, al acceder a ellos considera que debes apegarte a sus términos y condiciones.
Lecturas
Para conocer más acerca de Machine Learning, probabilidad y estadística, te sugerimos revisar lo siguiente:
- TIBCO. (s. f.). ¿Qué es Data Science? Recuperado de https://www.tibco.com/es/reference-center/what-is-data-science
Videos
Para conocer más acerca de Machine Learning, probabilidad y estadística, te sugerimos revisar lo siguiente:
- DataScience ForBusiness. (2019, 02 de septiembre). Data Science, Big Data, Machine Learning... ¿son lo mismo? [Archivo del video]. Recuperado de https://youtu.be/0iaAvNnw2hE

- Computadora con acceso a internet.

- Deberás revisar el tema Machine Learning, probabilidad y estadística.
