
Entender y aplicar el etiquetado de las partes de una oración.
En este tema entenderás cómo se forma una oración desde su base más simple hasta cómo ocupar esta estructura para la creación de etiquetados de las partes de una oración.
Los siguientes enlaces son externos a la Universidad Tecmilenio, al acceder a ellos considera que debes apegarte a sus términos y condiciones.
Para conocer más sobre etiqueta de secuencias, te recomendamos revisar el siguiente video:
KGP Talkie. (2019, 20 de octubre). NLP Tutorial 1 - Spam Text Message Classification using NLP, sklearn | Natural Language Processing [Archivo de video]. Recuperado de https://www.youtube.com/watch?v=mrF9MD56-wk
Construir un etiquetador POS.
El trabajo práctico que se realizará utiliza programación en Python 3 y la librería NLTK.
Esta pantalla se obtuvo directamente del software que se está explicando en la computadora, para fines educativos.
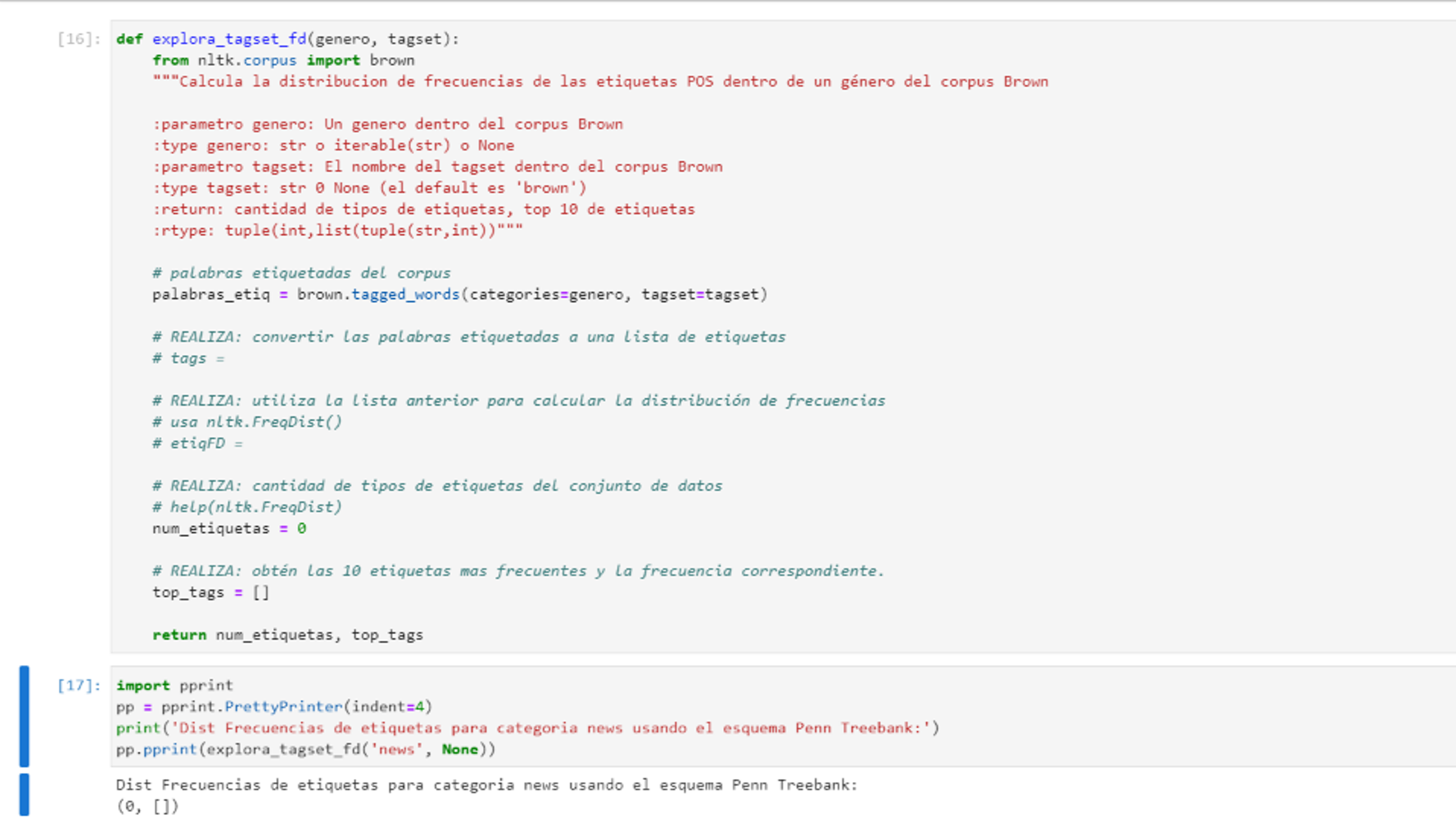
Esta pantalla se obtuvo directamente del software que se está explicando en la computadora, para fines educativos.
La función implementa cuatro tareas: convierte la lista de parejas (palabra, etiqueta) a una lista de etiquetas; utilizando las etiquetas calcula la distribución de frecuencias, calcula la cantidad de etiquetas en la distribución de frecuencias y regresa el número total de etiquetas y las 10 etiquetas más frecuentes.
Para probar la función es posible utilizar la instrucción de la línea 17 de la figura o cualquiera de las alternativas siguientes: explora_tagset_fd('science_fiction', 'universal'), explora_tagset_fd('science_fiction', None) o cualquier combinación de parámetros válidos de género y esquema de etiquetado.
Asegúrate de: