Contexto
Karla es ingeniero de software que ha estado trabajando con PSP desde que entró a trabajar a una compañía que se ha convertido en un referente en la consultoría de proyectos de software. Al inicio del año su jefe le asignó un proyecto al que se le asignaron 600 horas de trabajo de un programador a tiempo completo. A Karla esta estimación del esfuerzo requerido para obtener la funcionalidad completa le pareció muy baja, pues considera que el cliente espera cubrir una necesidad crítica para su negocio. Ella estima que deberían incluirse al menos 200 horas extras a la estimación inicial.

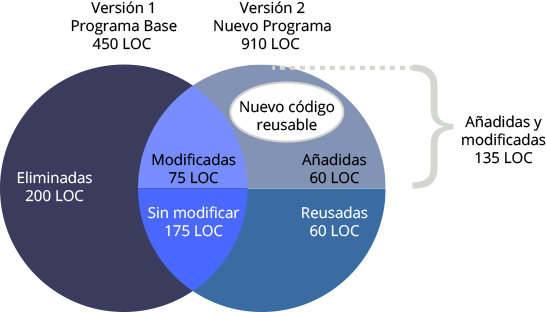
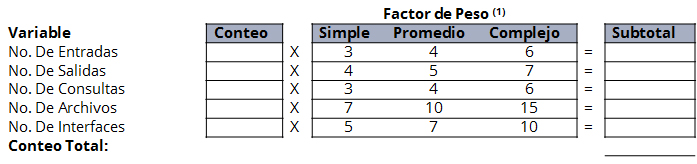
Ante esta discrepancia, Karla aprovecha una reunión con el gerente del proyecto para consultarle cómo es que llegaron a esa decisión. El gerente le confirmó que era una cantidad de líneas de código requeridas que fueron reutilizadas, y se realizó un cálculo de los Puntos de Función tomando en cuenta uno de los proyectos anteriores en los que se requirió una funcionalidad similar y se misma arquitectura de software. Karla se pregunta ¿cómo se estima la cantidad de líneas de código cuando se incorporan funciones de otros programas ?, ¿qué se refirió el gerente del proyecto cuando mencionó el término de puntos de función y qué relación tiene con la dimensión del tamaño del software?