8.1 Diseño de bases de datos y proceso de normalización
Es muy importante diseñar una base de datos correctamente antes de empezar a construirla, de lo contrario, es muy probable que más adelante tengas que modificarla dividiendo la información en otras tablas, uniendo tablas o moviendo varias columnas con el fin de lograr relaciones que MySQL pueda utilizar fácilmente. Aunque te cueste creerlo, las mejores herramientas para diseñar una base de datos son una hoja de papel y un lápiz.
Pero, ¿cómo empezar el diseño de una base de datos?
El proceso a seguir es bastante parecido al que harías en la planeación de cualquier proyecto. Primero escribe las preguntas que harían los usuarios acerca de la información que buscan, algunas de sus preguntas pueden ser parecidas a:
¿Cómo identificaré a los usuarios?
¿El usuario solo tiene una dirección?
¿Cómo encuentro su correo electrónico?, ¿lo necesito?
Obviamente estas preguntas pueden ser diferentes o más específicas dependiendo de tu proyecto.
Ahora bien, al proceso de separación de datos en tablas y la creación de PRIMARY KEYS se le llama normalización. Su principal objetivo es asegurarse de que cada pieza de información aparezca en la base de datos una sola vez. La duplicación de datos es ineficiente, ya que hace crecer a las bases de datos de manera innecesaria. Pero más importante, la presencia de duplicados crea el riesgo de que podrías actualizar sólo una fila de datos que están duplicados, creando inconsistencias que pueden causar graves errores.
En este proceso se llevan a cabo dos pasos:
Primera normalización
En este proceso no deben existir columnas con información duplicada. Además, todas las columnas deben contener un solo valor.
De igual manera debe existir un PRIMARY KEY para identificación.
Segunda normalización
La segunda normalización se refiere a la depuración de redundancias en múltiples filas. Sólo se puede aplicar la segunda normalización si se cumple con la primera. En esencia, en esta segunda ronda se eliminan los datos duplicados de las tablas.
Si cumples con estas dos normalizaciones es bastante probable que tengas una base de datos óptima y funcional, sin embargo, si quieres ser estricto puedes aplicar aún una tercera normalización. En ella se movería la información que no está directamente relacionada con la llave primaria pero sí con otra información de la tabla, hacia otras tablas separadas.
¿Debes de normalizar siempre las bases de datos?
La respuesta debe ser que no, pues hay que considerar diferentes factores, por ejemplo, si estás trabajando con un sitio de alto tráfico no debes normalizar la base de datos, esto se debe a que tienes que evitar que MySQL se congele. Recuerda que la normalización se basa en crear tablas específicas, por lo tanto, si hay muchas tablas, debes pedirle a MySQL múltiples consultas. Si esto ocurre en un sitio web muy popular se estarían haciendo cientos de consultas al mismo tiempo ¡imagina la situación! Esto ocasionaría que el sitio responda lentamente o que se congele.
Sin embargo, debes tener la sensibilidad para saber cuándo y cómo ejecutar una normalización, pues es una herramienta que te servirá bastante para mantener una base de datos eficiente. Puedes consultar un ejemplo de cómo implementar la normalización aquí.

8.2 Relaciones entre tablas en una base de datos
Después de normalizar tu base de datos, es necesario crear relaciones entre las tablas que las componen. Las relaciones funcionan encontrando coincidencias en la información de columnas clave, generalmente estas columnas se llaman igual en ambas tablas.

En la mayoría de los casos, la relación coincide con la primary key de la tabla que proporciona un identificador único para cada fila, con una entrada en la foreign key de la otra tabla. Por ejemplo, las ventas de libros se pueden asociar con los títulos específicos vendidos por la creación de una relación entre la columna de title_id en la tabla de títulos (primary key) y la columna de title_id en la tabla de ventas (foreign key).
Existen varios tipos de relaciones entre tablas de una base de datos, enseguida conocerás las más importantes.
Las relaciones uno-a-muchos son el tipo más común. En esta relación una fila en la tabla A puede tener muchos registros coincidentes en la tabla B, pero una fila en la tabla B sólo puede tener una fila coincidente en la tabla A. Por ejemplo, las tablas de editoriales y títulos tienen una relación de uno-a-muchos: cada editor produce muchos títulos, pero cada título proviene de un solo editor.
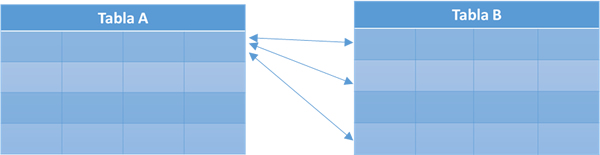
Nos conviene hacer una relación de uno a muchos, si sólo una de las columnas relacionadas es una primary key o tiene una restricción única. La primary key de una relación uno-a-muchos se denota por un símbolo de llave. La foreign key se representa por un símbolo de infinito.
Por otro lado están las relaciones muchos-a-muchos, en ellas una fila de la tabla A puede tener muchas coincidencias en varias filas de la tabla B y viceversa. Se crean este tipo de relaciones definiendo una tercera tabla denominada junction table, cuya primary key se compone de las foreign keys de las tablas A y B.
Por ejemplo, la tabla Authors y la tabla de Titles tienen una relación muchos-a-muchos que se define por una relación uno-a-muchos de cada una de estas tablas para la tabla AuthorsTitles. La primary key de la tabla AuthorsTitles es la combinación de la columna Author_id (primary key de la tabla Authors) y la columna de Title_id (primary key de la tabla Titles).
Observa este ejemplo de relaciones muchos a muchos.
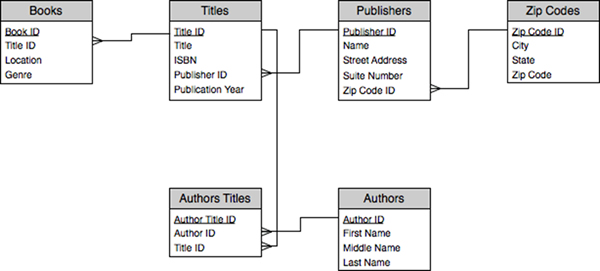
Imagen obtenida de http://www.atpm.com/14.04/images/filemaking-10.png Solo para fines educativos.
Finalmente están las relaciones uno-a-uno, en ellas una fila en la tabla A no puede tener más de una coincidencia con otra fila de la tabla B y viceversa; una relación de este tipo es creada si ambas columnas son primary keys o tienen restricciones únicas. En este caso la primary key y la foreign key se identifican con el símbolo de llave.
Esta relación no es común porque la mayoría de la información que se maneja de esta manera, estaría alojada en una sola tabla. No obstante, el uso de este tipo de relación es conveniente en ciertos casos, por ejemplo:
- Para dividir una tabla con muchas columnas.
- Para aislar una parte de una tabla por razones de seguridad.
- Para guardar datos de corta vida y que pueden ser fácilmente eliminados borrando la tabla.
- Para guardar información que aplica solamente a un subconjunto de la tabla principal.
8.3 Respaldo y restauración de bases de datos
En ocasiones los proyectos que realizas son muy complejos y requieren de una gran logística para llevarlos a cabo, sin embargo en ocasiones pueden ocurrir desperfectos que te orillarán a tener una versión de respaldo. Enseguida vas a explorar la manera de hacer respaldos y restauraciones de bases de datos mediante phpMyAdmin.
Para respaldar una base de datos, realiza lo siguiente:
- Desde phpMyAdmin selecciona la base de datos que quieres respaldar haciendo clic en la lista de la izquierda de la pantalla.
- Haz clic en la pestaña EXPORT, la cual te muestra una nueva pantalla con las opciones para la exportación de las tablas. Si quieres exportar todas las tablas usa el modo Quick, si quieres seleccionar las tablas y ver todas las opciones para exportación usa Custom.
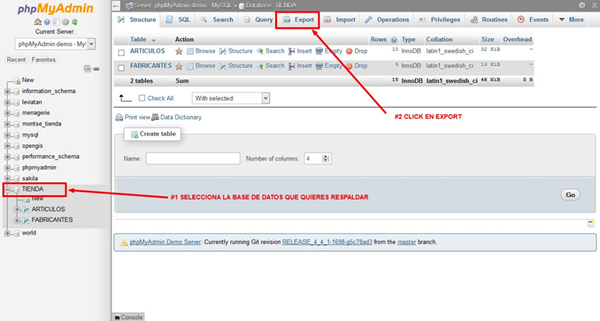
- En el menú de formatos selecciona el que te sea más conveniente. Es recomendable que hagas respaldo en SQL y en algún otro formato extra para asegurar más la información.
- Cuando estés listo haz clic en GO. Un cuadro de diálogo aparecerá para que selecciones donde guardar el archivo localmente.
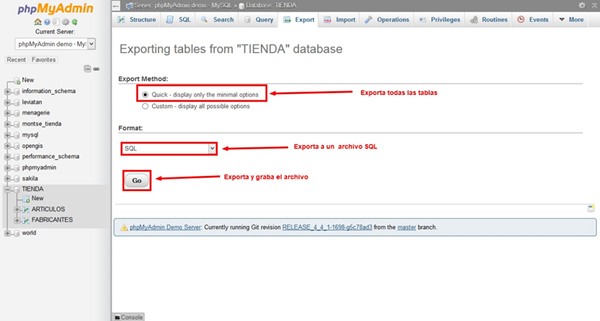
Ahora bien, para restaurar una base de datos puedes llevar a cabo los siguientes pasos:
- Desde phpMyAdmin crea una nueva base de datos. A esta base de datos la cargaremos con el respaldo que acabas de hacer.
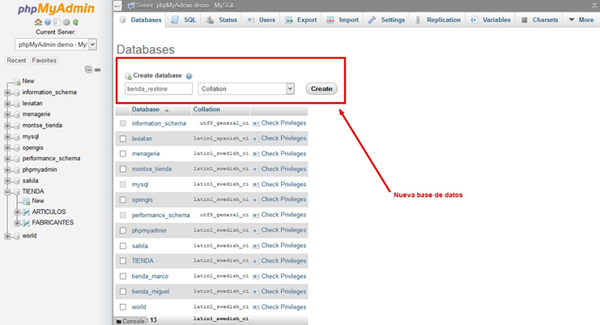
-
Selecciona la pestaña IMPORT y carga el archivo de respaldo. El archivo debe subirse en formato zip siguiendo este ejemplo: nombre_db.sql.zip. Si el respaldo está en formato SQL no es necesario que el archivo esté en formato zip.
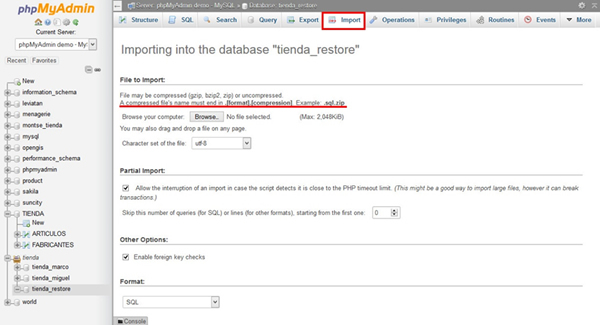
- Carga el archivo y haz clic en el botón GO. Se cargará la copia de seguridad, se ejecutarán los comandos SQL y se volverá a crear la base de datos.
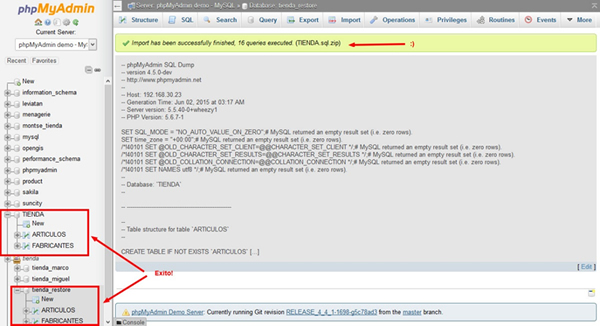
El respaldo y restauración de las bases de datos puede hacerse de otras maneras, por ejemplo usando mysqldump o usando línea de comando.






