La minería de datos puede definirse como un proceso de descubrimiento de relaciones nuevas y significativas, patrones y tendencias al examinar grandes cantidades de datos (Hair, 2007).
La disponibilidad de grandes volúmenes de información y el uso generalizado de herramientas informáticas ha transformado el análisis de datos orientándolo hacia determinadas técnicas especializadas englobadas bajo el nombre de minería de datos o Data Mining.
Las técnicas de minería de datos persiguen el descubrimiento automático del conocimiento contenido en la información almacenada, de modo ordenado, en grandes bases de datos. Estas técnicas tienen como objetivo descubrir patrones, perfiles y tendencias a través del análisis de los datos utilizando tecnologías de reconocimiento de patrones, redes neuronales, lógica difusa, algoritmos genéticos y otras técnicas avanzadas de análisis de datos (Tusell, 2012).
Con la informatización de las organizaciones y la aparición de aplicaciones software operacionales sobre el sistema de información, la finalidad principal de los sistemas de información es dar soporte a los procesos básicos de la organización (ventas, producción, personal…). Una vez satisfecha la necesidad de tener un soporte informático para los procesos básicos de la organización (sistemas de información para la gestión), las organizaciones exigen nuevas prestaciones de los sistemas de información (sistemas de información para la toma de decisiones).
De esta forma han aparecido diferentes herramientas de negocio para la toma de decisiones (DSS o Decision Support Systems) que coexisten: EIS (Executive Information System), OLAP (On-Line Analytical Proccesing), consultas e informes, y las propias herramientas de minería de datos.
Todas estas herramientas necesitan de la existencia previa de un almacén de datos (Data Warehouse). El almacén de datos es una colección de datos orientada a un dominio, integrada, no volátil y variante en el tiempo para ayudar en la toma de decisiones. Es un conjunto de datos históricos, internos o externos y descriptivos de un contexto o área de estudio, que están integrados y organizados de tal forma que permiten aplicar eficientemente herramientas para resumir, describir y analizar los datos con el fin de ayudar en la toma de decisiones estratégicas (Tusell, 2012).
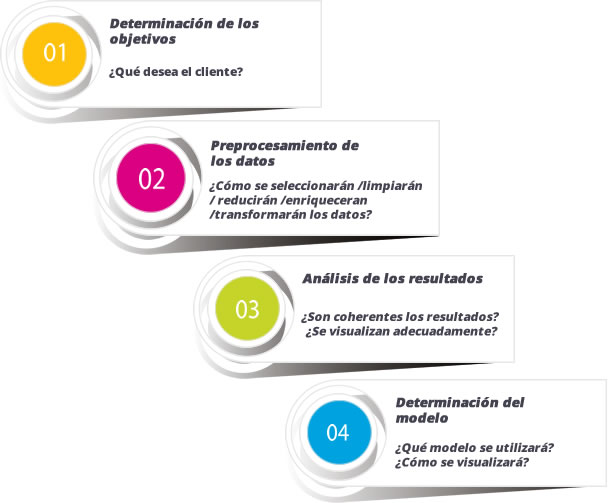
La minería de datos es una etapa del proceso de extracción de conocimiento a partir de datos (KDD). Este proceso consta de varias fases como la preparación de datos (selección, limpieza y transformación), su exploración y auditoría, minería de datos propiamente dicha (desarrollo de modelos y análisis de datos), evaluación, difusión y utilización de modelos (output). Además, el proceso de extracción del conocimiento incorpora muy diferentes técnicas (árboles de decisión, regresión lineal, redes neuronales artificiales, técnicas bayesianas, máquinas de soporte vertical, etc.) de campos diversos (aprendizaje automático e inteligencia artificial), estadística, bases de datos, etc. Y aborda una tipología variada de problemas (clasificación, categorización, estimación /regresión, agrupamiento, etc.). (Hair, 2007; Pérez 2004).

12.1 Árboles de decisión
Los árboles de decisión aprenden bajo un sistema englobado en una metodología de aprendizaje supervisado. La representación que se utiliza para las descripciones del concepto adquirido es el árbol de decisión, que consiste en una representación de los conocimientos relativamente simple y que es una de las causas por la que los procedimientos utilizados en su aprendizaje son más sencillos que utilizan lenguajes de representación más potentes, como redes semánticas, representaciones en lógica de primer orden, etc.
Un árbol de decisión puede interpretarse esencialmente como una serie de reglas compactadas para su representación, en forma de árbol. Dado un conjunto de ejemplos, estructurados como vectores de pares ordenados atributo-valor, de acuerdo con el formato general en el aprendizaje inductivo a partir de ejemplos, el concepto que estos sistemas adquieren durante el proceso de aprendizaje consiste en un árbol. Cada eje está etiquetado con un par atributo-valor y las hojas con una clase, de forma que la trayectoria que determina desde la raíz los pares de un ejemplo de entrenamiento alcanzan una hoja etiquetada —normalmente— con la clase del ejemplo. La clasificación de un ejemplo nuevo del que se desconoce su clase se hace con la misma técnica, solamente que en ese caso al atributo clase, cuyo valor se desconoce, se le asigna de acuerdo con la etiqueta de la hoja a la que se accede con ese ejemplo (Hair, 2007; Tusell, 2012).
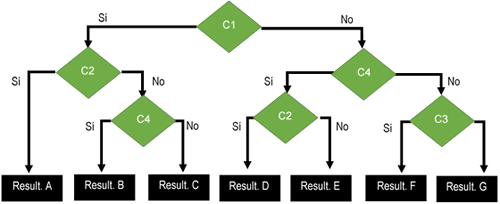
Acorde a Hair (2007) Existen 3 algoritmos de árboles de decisión:
- El sistema ID3
Genera el árbol de decisión seleccionando un atributo como raíz del árbol y crea una rama con cada uno de los posibles valores de dicho atributo. Cada rama resultante (nuevo nodo del árbol), se realiza el mismo proceso hasta que todos los ejemplos se clasifiquen a través de uno de los caminos del árbol. El nodo final de cada camino será un nodo hoja, al que se le asignará la clase correspondiente. Así, el objetivo de los árboles de decisión es obtener reglas o relaciones que permitan clasificar a partir de los atributos.
En cada nodo del árbol de decisión se debe seleccionar un atributo para seguir dividiendo, y el criterio que se toma para elegirlo es: se selecciona el atributo que mejor separe (ordene) los ejemplos de acuerdo a las clases. Para ello se emplea la entropía, que es una medida de cómo está ordenado el universo. La teoría de la información (basada en la entropía) calcula el número de bits (información, preguntas sobre atributos) que hace falta suministrar para conocer la clase a la que pertenece un ejemplo. Cuanto menor sea el valor de la entropía, menor será la incertidumbre y más útil será el atributo para la clasificación.
- El sistema C4.5
Trata con atributos de valores discretos o continuos. En el primer caso, el árbol de decisión generado tendrá tantas ramas como valores posibles tome el atributo. Si los valores del atributo son continuos, no clasifica correctamente los ejemplos dados. Debido a la complejidad que estriban los valores continuos (que se verán clasificados en múltiples ramas), el árbol resultante puede ser bastante complejo, con trayectorias largas y muy desiguales.
Para facilitar la comprensión, se propuso:
- El empleo del concepto razón de ganancia.
- Construir árboles de decisión cuando algunos de los ejemplos presentan valores desconocidos para algunos de los atributos.
- Trabajar con atributos que presenten valores continuos.
- La poda de los árboles de decisión.
- Obtención de reglas de clasificación.
Para facilitar la comprensión del árbol puede realizarse una poda del mismo.
- Decisión stump (árbol de un solo nivel)
Este tiene un algoritmo sumamente sencillo que genera un árbol de decisión de un solo nivel, utilizando un único atributo para construir el árbol de decisión. La elección del único atributo que formará parte del árbol se realizará basándose en la ganancia de información, y a pesar de su simplicidad, en algunos problemas puede llegar a conseguir resultados interesantes.
El árbol de decisión tendrá 3 ramas: una para cuando el atributo sea desconocido, y las otras dos para el caso de que el valor del atributo del ejemplo de test sea igual a un valor concreto del atributo o distinto a dicho valor; en caso de los atributos simbólicos, o que el valor del ejemplo de test sea mayor o menor a un determinado valor en el caso de atributos numéricos. En el caso de atributos simbólicos se busca el mejor punto de ruptura. Deben tenerse en cuenta cuatro posibles casos al calcular la ganancia de información:
- Atributo simbólico y clase simbólica
- Atributo numérico y clase simbólica
- Atributo simbólico y clase numérica
- Atributo numérico y clase numérica
12.2 Redes neuronales
Las redes neuronales constituyen una nueva forma de analizar la información con una diferencia fundamental con respecto a las técnicas tradicionales: son capaces de detectar y aprender complejos patrones y características dentro de los datos. Se comportan de forma parecida a nuestro cerebro, aprendiendo de la experiencia y del pasado, y aplicando tal conocimiento a la resolución de problemas nuevos (Hair, 2007).
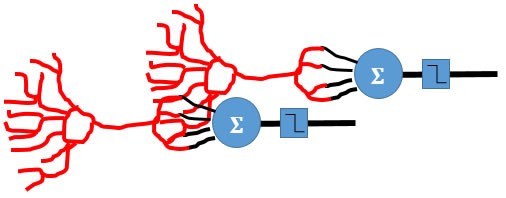
Este aprendizaje se obtiene como resultado del adiestramiento, y éste permite la sencillez y la potencia de adaptación y evolución ante una realidad cambiante y muy dinámica. Una vez adiestradas las redes de neuronas pueden hacer previsiones, clasificaciones y segmentación. Presentan, además, una eficiencia y fiabilidad similar a los métodos estadísticos y sistemas expertos, en la mayoría de los casos. En aquellos casos de muy alta complejidad las redes neuronales se muestran como especialmente útiles dada la dificultad de modelado que supone para otras técnicas (Tusell, 2012). Sin embargo, las redes de neuronas tienen el inconveniente de la dificultad de acceder y comprender los modelos que generan y presentan dificultades para extraer reglas de tales modelos. Otra característica es que son capaces de trabajar con datos incompletos e incluso, contradictorios lo que, dependiendo del problema, puede resultar una ventaja o un inconveniente. Las redes neuronales poseen las dos formas de paradigma que usan: el no supervisado y el supervisado que suele usar el paradigma del “backpropagation” (Julián, 2014).
Las redes neuronales están siendo utilizadas en distintos y variados sectores como la industria, el gobierno, el ejército, las comunicaciones, la investigación aeroespacial, la banca y las finanzas, los seguros, la medicina, la distribución, la robótica, el marketing, etc. En la actualidad se está estudiando la posibilidad de utilizar técnicas avanzadas y novedosas como los algoritmos genéticos para crear paradigmas que mejoren el adiestramiento y la propia selección y diseño de la arquitectura de la red (número de capas y neuronas), diseño que ahora debe realizarse con base en la experiencia del analista y para cada problema concreto (Tusell, 2012).
Las redes neuronales se construyen estructurando en una serie de niveles o capas (al menos tres: entrada, procesamiento u oculta y salida) compuestas por nodos o “neuronas”. Tanto el umbral como los pesos son constantes y se inicializarán aleatoriamente y durante el proceso de aprendizaje serán modificados. La salida neuronal se define mediante una ecuación.
Cada neurona está conectada a todas las neuronas de las capas anterior y posterior a través de los pesos o “dendritas”.
Cuando un nodo recibe las entradas o “estímulos” de otras los procesa para producir una salida que trasmite a la siguiente capa de neuronas. La señal de salida tendrá una intensidad fruto de la combinación de la intensidad de las señales de entrada y de los pesos que las transmiten. Los pesos o dendritas tienen un valor distinto para cada par de neuronas que conectan pudiendo así fortalecer o debilitar la conexión o comunicación entre neuronas particulares. Los pesos son modificados durante el proceso de adiestramiento (Tusell, 2012).
El diseño de la red de neuronas consistirá, entre otras cosas, en la definición del número de neuronas de las tres capas de la red. Las neuronas de la capa de entrada y las de la capa de salida vienen dadas por el problema a resolver, dependiendo de la codificación de la información. En cuanto al número de neuronas ocultas se determinará por prueba y error. Por último, debe tenerse en cuenta que la estructura de las neuronas de la capa de entrada se simplifica, dado que su salida es igual a su entrada: no hay umbral ni función de salida (Julián, 2014).
Existen distintos métodos o paradigmas mediante los cuales estos pesos pueden ser variados durante el adiestramiento, de los cuales el más utilizado es el de retropropagación o backpropagation. Este paradigma varía los pesos de acuerdo a las diferencias encontradas entre la salida obtenida y la que debería obtenerse. De esta forma, si las diferencias son grandes, se modifica el modelo de forma importante, y según van siendo menores, se va convergiendo a un modelo final estable.
En cuanto al criterio de parada, se debe calcular la suma de los errores en los patrones de entrenamiento. Si el error es constante de un ciclo a otro, los parámetros dejan de sufrir modificaciones y se obtiene así el error mínimo. Por otro lado, también se debe tener en cuenta el error en los patrones de validación, que se presentarán a la red tras n ciclos de aprendizaje. Si el error en los patrones de validación evoluciona favorablemente, se continúa con el proceso de aprendizaje; si el error no desciende, se detiene el aprendizaje (Tusell, 2012).