1.1 Características principales de los sistemas de visión
Los sistemas de visión hacen referencia a la detección de datos de visión y su interpretación por una computadora. Éste se encuentra constituido básicamente por una cámara y equipos de digitalización, una computadora digital y los elementos de hardware y software necesarios para su interconexión. Esto último se suele referir a un preprocesador. Las tres características principales para el funcionamiento de un sistema de visión son los siguientes:
- Detección y digitalización de datos de imagen
- Análisis y procesamiento de imágenes
- Aplicación
Las relaciones entre las tres funciones se ilustran en el diagrama siguiente:
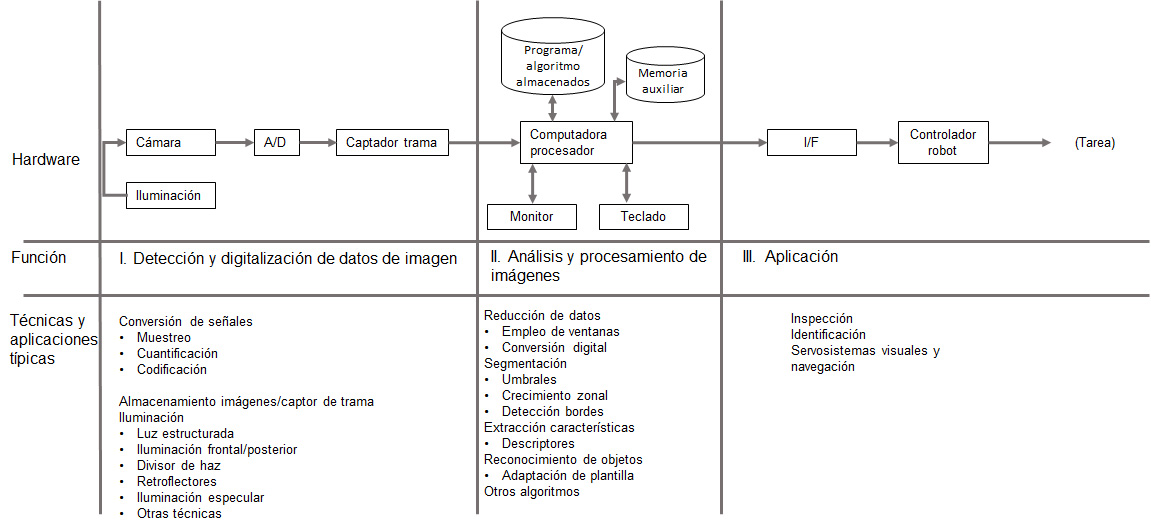
Groover, M., Weiss, M, Nagael, R. y Odrey, N. (1995). Industrial Robotics Technology, Programming and Applications. EE. UU: McGraw Hill.
Las funciones de detección y digitalización implican la entrada de datos de visión por medio de una cámara enfocada en la escena de interés. Se emplean técnicas de iluminación especiales para obtener una imagen de suficiente contraste para su posterior procesamiento. La imagen visionada por la cámara se suele digitalizar y almacenar en memoria de computadora. La imagen digital se denomina un campo de datos de visión y se suele capturar mediante un dispositivo de hardware denominado un captador de trama.
Estos dispositivos son capaces de digitalizar imágenes a una velocidad de 30 cuadros por segundo. Los cuadros están constituidos por una matriz de proyecciones de representación de datos de la escena detectada por la cámara. Los elementos de la matriz se denominan elementos de imagen o píxel. El número de píxel se determina mediante un proceso de muestreo realizado en cada cuadro de imagen. Un píxel individual es la proyección de una pequeña parte de la escena, que reduce esa parte a un valor único. El valor es una medida de la intensidad de luz para ese elemento de la escena. La intensidad de cada píxel se convierte en un valor digital. Este valor corresponde a la función obtenida tras el resultado de la medida o muestreos realizados a intervalos de tiempo espaciados regularmente, siendo el valor de dicha función un número positivo y entero. Los valores que esta función forma en cada punto dependen del brillo que presenta en esos puntos la imagen original.

La matriz de imagen digitalizada para cada cuadro se almacena y luego se somete a las funciones de procesamiento de imágenes y análisis para reducción de datos e interpretación de la imagen. Estos pasos se requieren para permitir la aplicación en tiempo real del análisis de visión requerido en las aplicaciones de robótica. Normalmente, un cuadro de imagen tendrá unos umbrales para obtener una imagen binaria, y luego varias medidas de características reducirán todavía más la representación de datos de la imagen. Esta reducción de datos puede cambiar la representación de un cuadro desde varios centenares de bytes de datos de valores de características. Los datos de característica resultante pueden analizarse en el tiempo disponible para la acción por el sistema robot.
Varias técnicas para calcular los valores de características pueden programarse en la computadora para obtener descriptores de la imagen que están en concordancia con los valores anteriormente calculados, que están almacenados en la computadora. Estos descriptores incluyen las características de forma y tamaño que pueden calcularse con facilidad a partir de la matriz de imágenes con umbrales. Algunas de estas técnicas utilizadas en el procesamiento de imágenes y análisis se examinarán en el capítulo 8 del presente módulo.
Para realizar el procesamiento de imágenes y su análisis, el sistema de visión debe capacitarse con frecuencia. En este proceso se obtiene información sobre los objetos de prototipo y se almacena como modelos de computadora. La información recogida durante la capacitación está constituida por características tales como el área del proyecto, su longitud perimétrica, diámetros mayor y menor y otras características similares. Durante la posterior operación del sistema, los valores calculados en objetos desconocidos visionados por la cámara se comparan con los modelos de computadora para determinar si se produjo una coincidencia. En el capítulo 9 del presente módulo se examinará el adiestramiento de un sistema de visión.
Las aplicaciones actuales de la visión de máquina en la robótica incluyen la inspección, la identificación de piezas, la localización y la orientación. Está en curso, los trabajos de investigación sobre aplicaciones avanzadas de la visión de máquina para su empleo en tareas complejas de inspección, guiado y navegación.

Algunas de las aplicaciones más usuales de visión de máquina son tareas de inspección que no implican el empleo de un robot industrial. Una aplicación típica es aquella en donde el sistema de visión de máquina se instala en una línea de producción de alta velocidad para aceptar o rechazar las piezas fabricadas en la línea. Las piezas no aceptables se sacan fuera de la línea mediante algún dispositivo mecánico, que está comunicado con el sistema de visión.
Se puede considerar que las aplicaciones de visión de máquina tienen tres niveles de dificultad. Estos niveles dependen de si los elementos objeto de visión están controlados en posición o apariencia. El control de la posición de un elemento en un entorno de fabricación suele necesitar un montaje de sujeción preciso. El control de la apariencia de un elemento se realiza mediante las técnicas de iluminación. Los tres niveles de dificultad utilizados para categorizar las aplicaciones de visión de máquina en el ámbito industrial son los siguientes:
- El objeto se puede controlar en posición y apariencia.
- El objeto se puede controlar por posición o apariencia, pero no ambas cosas a la vez.
- El objeto no se puede controlar ni por posición ni por apariencia.
El tercer nivel de dificultad exige capacidades de visión avanzadas. El objetivo de la técnica de las aplicaciones de visión es conseguir el nivel más bajo de dificultad, con lo que se reducirá también el nivel de sofisticación del sistema de visión requerido en la aplicación. Por ejemplo, uno de los problemas que suele surgir en el reconocimiento de un objeto es que el proceso de reconocimiento se facilita si el objeto está en la orientación y posición conocidas. Las piezas en una fábrica no suelen estar situadas de esa forma. Este problema puede reducirse desde un tercer nivel hasta un primer nivel de dificultad mediante la sujeción de las piezas y la utilización de técnicas tales como la iluminación estructurada para controlar la apariencia.
En términos generales, las aplicaciones de la robótica de la visión de máquina están dentro de una de las tres categorías indicadas a continuación:
Haz clic en cada botón para obtener más información
1. Inspección.
En la primera categoría, la función primaria es el proceso de inspección. En este caso, el objetivo de la inspección de visión de máquina se incluye la comprobación de los defectos en bruto de superficies, detección de defectos en etiquetados, medición de la exactitud dimensional y comprobación para detectar la presencia de agujeros y otras características en una pieza. Cuando estas clases de operaciones de inspección se realizan manualmente, existe una tendencia de error. Con la visión de máquina, estos procedimientos se llevan en forma automática, un porcentaje de inspección de 100% y, por norma general, en un tiempo mucho menor.
2. Identificación.
La segunda categoría, la identificación, hace referencia a las aplicaciones en las que el propósito del sistema de visión es reconocer y clasificar un objeto en vez de inspeccionarlo. La inspección implica la aceptación o rechazo de la pieza. La identificación lleva consigo un proceso de reconocimiento en el que la propia pieza, su posición u orientación sea determinada. Entre las aplicaciones de identificación de la visión de máquina se incluyen la clasificación de las piezas, paletización y despaletización y captación de piezas que se orientan de forma aleatoria desde una banda transportadora.
3. Servo presentación visual y navegación.
En la tercera categoría de aplicación, servo presentación visual, el objetivo del sistema de visión es dirigir las acciones del robot basándose en su entrada visual. El ejemplo genérico es donde se utiliza el sistema de visión de máquina para controlar la trayectoria del efector final del robot hacia un objeto dentro del espacio de trabajo. Entre los ejemplos industriales de esta aplicación se incluyen el posicionamiento de una pieza, recuperación de piezas en movimiento a lo largo de un transportador, recuperación y reorientación de piezas en movimiento a lo largo de un transportador, montaje, recogida de recipientes y seguimiento de la costura en la soldadura por arco continua.
1.2 Modelos usados en los sistemas de visión
La meta de los distintos modelos de cámaras es la geometría de la proyección de puntos en 3D, curvas y superficies sobre una superficie 2D, ya sea en el plano de vista o plano imaginario.
Los dos tipos principales de modelos son los siguientes:
- Modelo de lente delgada.
- Modelo pinhole (agujero de alfiler).
Modelo de lente delgada. Las cámaras más modernas utilizan lentes para enfocar la luz sobre la superficie plana. Esto se hace porque de esta manera uno puede capturar suficiente luz en un periodo de tiempo lo suficientemente corto en que los objetos no se mueven apreciablemente, y la imagen es lo suficientemente brillante para mostrar detalles significantes sobre un amplio rango de intensidades y contrastes.
Hay una amplia gama de dispositivos de formación de imágenes disponibles en el mercado. En una cámara convencional, la vista del plano contiene químicos foto reactivos; en nuestro caso hacemos referencia a cámaras de estado sólido para la visión del robot, las cuales incluyen dispositivos acoplados por carga (CCD). Este método se utiliza para obtener una imagen digitalizada (utilizando una cámara digital). En esta tecnología la imagen se proyecta por una cámara de video sobre el CCD, que detecta, almacena y extrae por lectura la carga acumulada generada por la luz en cada parte de la imagen. La detección de la luz se produce mediante la absorción de luz en un substrato fotoconductor (por ejemplo, silicio). Las cargas se acumulan bajo electrodos de control positivos en cubetas aisladas debido a las tensiones aplicadas a los electrodos centrales. Cada cubeta aislada representa un solo píxel y puede transferirse a registros de almacenamiento de salida variando las tensiones en los electrodos de controles metálicos.
Los modelos de lente delgada pueden ser bastante complejos, específicamente para lentes compuestos encontrados en la mayoría de las cámaras. A partir de este punto consideraremos quizás el caso más simple, conocido como el modelo de lente delgada. En este modelo, los rayos de luz emitidos desde un punto viajando a través de un camino recto por la lente, cubren un punto detrás de la lente. La cantidad clave gobernando este comportamiento es llamada como la longitud focal del lente. La longitud focal, puede ser definida como la distancia detrás de los lentes para los cuales los rayos desde una fuente de distancia infinita convergen en un foco.
Modelo pinhole. Está cámara es una idealización de una lente delgada como apertura encogida a cero. La luz desde un punto viaja alrededor de un sencillo camino recto a lo largo de un agujero del tamaño de un orificio de alfiler, sobre la vista plana. El objeto es imaginado al revés sobre el plano de la imagen. Existe otra manera de pensar acerca del modelo pinhole. Suponga que está viendo una escena con un ojo mirando a través de una ventana cuadrada, y dibuje una pintura sobre lo que está viendo a través de la ventana.
La imagen que se obtiene corresponde al dibujo de un rayo desde la posición del ojo e intersectando éste con la ventana. Esto es equivalente al modelo de la cámara pinhole, excepto que el plano de la vista está enfrente del ojo en lugar de estar detrás de él, y la imagen aparece boca arriba, más bien al revés (es decir, el punto del ojo reemplaza el orificio de alfiler). Para observar esto considera el rastreo de rayos desde los puntos de escena a través de la vista de plano detrás del punto del ojo y uno enfrente del, tal como se mostró en la figura anterior.
1.3 Criterio de selección de un sistema de visión.
En los sistemas de visión artificial es necesario utilizar ópticas de calidad para tener la mejor imagen posible y permitir las medidas con la mejor precisión. Para definir el tipo de óptica se deben de seguir una serie de criterios de selección:
- Las especificaciones del sensor de la cámara.
- El tamaño y geometría del objeto.
- La distancia y el espacio disponible.
Así como los elementos que componen las lentes:
- Anillo de enfoque: cuánto más cerca enfocamos, más sobresale el objetivo.
- Diafragma: se enfoca para girar la entrada de luz a la cámara. Su escala suele ser: 16,11, 1.8. A mayor número seleccionado, menor abertura del diafragma y mayor profundidad de campo.
- Velocidad de obturación: selecciona el tiempo que estará abierto el diafragma. Su escala suele ser: 1/1, ½, 1/250, 1/1000. Para obtener imágenes nítidas de objetos que se desplazan a gran velocidad hay que seleccionar velocidades de obturación altas.
- Longitud o distancia focal: valor en milímetros que nos informa la distancia entre el plano focal (CCD) y el centro del objetivo.
- Profundidad de campo: espacio en el cual se ve el objeto totalmente nítido. Depende de la longitud focal de la lente empleada.
- Precisión de la medida: depende exclusivamente del campo de medida y de la resolución de la cámara.
Con base en sus características, las lentes poseen la siguiente clasificación:
Características |
Gran angular
(<50 milímetros) |
Standard
(= 50 milímetros) |
Teleobjetivo
(> 50 milímetros) |
Angulo de visión |
70 grados |
50 grados |
30 grados |
Tamaño |
Pequeño |
Medio |
Grande |
Luminosidad |
Muy luminoso |
Luminoso |
Poco luminoso |
Perspectiva |
Separación de objetos |
Reproducción correcta |
Objetos próximos |
Profundidad de campo |
Muy grande |
Media |
Muy pequeña |
Posibilidades |
Grandes espacios |
Espacios no muy grandes |
Para acercar objetos |
Adicionalmente, es importante considerar la luz visible, el cual es un tipo de radiación electromagnética que puede ser detectado por el ojo humano. Los colores que percibimos en un objeto son determinados por la naturaleza de luz reflejada en dicho objeto.
Luz monocromática: es la luz que no tiene color, su único atributo es su intensidad o cantidad. En general usamos el término nivel de gris para definirla, porque ésta va desde el negro hasta el blanco pasando por una gama de grises.
Luz cromática: es la luz de color, se usan tres cantidades para describir su calidad.
- Radiancia: cantidad total de energía que fluye de una fuente de luz.
- Luminancia: cantidad de energía que un observador percibe de una fuente de luz.
- Brillo: es la iluminación subjetiva, engloba la noción de intensidad.
1.4 Elementos de calibración.
La calibración de una cámara es el primer paso para la solución de aplicaciones donde es necesario obtener datos cuantitativos de la imagen. Aunque es posible obtener información de la escena a partir de imágenes tomadas sin calibrar cámaras, el proceso de calibración es esencial cuando se trata de la obtención de mediciones del mismo.
Una calibración exacta de la cámara permite obtener distancias del mundo real a partir de imágenes tomadas de la misma. Con esta información es posible resolver aplicaciones de ensamble de partes industriales, evitar obstáculos en la navegación de un robot, controlar un brazo robótico o desarrollar la planificación de una ruta de trabajo. Si por el contrario nos centramos en la reconstrucción 3D de objetos, cada punto de la imagen determina un haz óptico el cual pasa por el centro óptico de la cámara en escena. La gestión de múltiples imágenes de la misma escena en la que no hay movimiento, se puede relacionar con los dos haces ópticos para la posición de los puntos 3D en la escena.
En este caso es necesario resolver el paso anterior de correspondencias de un objeto en diferentes imágenes. Una vez que ha sido posible realizar la reconstrucción 3D del objeto, puede ser comparado con un modelo almacenado para determinar el resultado de imperfecciones en el mismo proceso de manufactura, lo que implica que una mejora significativa no puede sobre la inspección humana.
Técnicas para la calibración de la cámara.
Haz clic en cada concepto para ver a detalle.
La calibración fotogramétrica se realiza por la observación de patrones cuya geometría en un espacio 3D es conocida con un buen nivel de precisión. Los patrones estándares de calibración están normalmente posicionados en dos o tres planos ortogonales entre ellos. En algunos casos, sólo se maneja un único plano, cuya translación es bien conocida. Este tipo de calibración requiere una configuración compleja, pero sus resultados son eficientes.
Este método se basa en el movimiento de la cámara de observación de una escena estática mientras viaja utilizando sólo la información de la imagen. La rigidez de la escena generalmente impone restricciones sobre los parámetros de la cámara. Tres imágenes adoptadas por una sola cámara con los parámetros intrínsecos son suficiente para los parámetros intrínsecos y extrínsecos, aunque esta técnica es muy flexible, no está maduro todavía.
El modelo de cámara tradicionalmente usado para pasar coordenadas reales 3D a coordenadas reales 2D pertenecientes a la imagen capturada, por lo general se utiliza el modelo de proyección en perspectiva llamado modelo pinhole. En este modelo todos los rayos de un determinado objeto pasan a través de un fino agujero para impactar el sensor de imagen. Dado que los lentes no tienen este comportamiento lineal, el modelo de orificio en aguja de alfiler (pinhole) debe ser corregido con un valor de distorsión, es decir, debe ser complementada con los parámetros que corrigen su comportamiento y enfoque ideal, en la medida de lo posible, proporcionar el comportamiento real del objetivo. El sistema de referencia de la cámara se coloca en el centro de la proyección, el eje z, coincidiendo con dicho sistema con el eje óptico, también llamado eje axial. En esta disposición de ejes, el plano de la imagen de coordenadas u, v, se encuentra a una distancia igual a la longitud focal de la distancia de la lente perpendicular al eje óptico. La intersección del eje de la óptica con el plano de la imagen se llama el punto principal. El centro de proyección de la cámara C se supone constante, pero es un desconocido priori. El plano de la imagen es por lo general colocado en frente del centro de proyección C para tomar una fotografía sin inversión.
El problema consiste en encontrar y resolver un modelo matemático de cómo la cámara ve la escena. Entiéndase por resolver al proceso de hallazgo de un conjunto de valores denominados parámetros, por lo que por este procedimiento permiten obtener información tridimensional a partir de imágenes.
Debido a que se obtienen los parámetros de calibración que participan en el proceso de formación de imágenes, a continuación, la calibración es el proceso por el cual se da la relación entre las coordenadas tridimensionales de los objetos en el entorno con los correspondientes proyecciones de imágenes bidimensionales fijados.
Técnicas de acuerdo con el destino de calibración
Dependiendo del objeto que se utiliza para calibrar, puede resaltar dos tipos de calibración, coplanares y no coplanares.
- Coplanar: El objeto utilizado es plano, con un patrón impreso que se llama cuadrícula de calibración, por ejemplo el que se muestra en la siguiente figura:

Imagen obtenida de http://gdsproc.com/congreso/capacho_stsiva_2010_1.pdf Sólo para fines educativos
- No Coplanar: El objeto utilizado es típicamente un cubo, en donde las diferentes caras son el mismo patrón impreso o una rejilla compuesta de dos planos, cada uno con el mismo patrón como el que se muestra en la siguiente figura. Un objeto de puntos de posiciones conocidas tridimensionales se conocen como puntos de calibración.

Imagen obtenida de http://gdsproc.com/congreso/capacho_stsiva_2010_1.pdf Sólo para fines educativos
1.5 Ajuste de enfoque manual y automático.
Calibración manual.
Las cámaras o sensores de imagen son los elementos responsables de la captura de información de escenas de luz y transmiten al equipo como señal analógica o digital. Una vez que la imagen ha sido tomada por la cámara de video, la tarjeta de adquisición de datos y el procesador de imágenes reciben la señal analógica enviada por él, para convertirla en una señal digital para su procesamiento.
La calibración de una cámara es una necesidad de las mediciones de la escena a partir de imágenes en el mismo paso. La precisión de la calibración posteriormente determina la precisión de las mediciones que se hacen a partir de imágenes. Es por esta razón por la que es esencial calibrar la cámara con plenas garantías de que los parámetros obtenidos son más cercanos a los valores reales. Este compromiso implica la elección de un método de ajuste de calibración y el uso adecuado de los mismos.
Hay diferentes métodos de ajustes manuales, así como distintas formas de clasificarlos. En esta sección se referencia algunos de los métodos que comúnmente se utilizan:
Método Tsai.
Método de Tsai representa un proceso de calibración clásico basado en mediciones de coordenadas de puntos de una plantilla 3D con relación a un punto de referencia fijo. Esto muestra excelentes resultados, una sola imagen de la calibración que se requiera, aunque se necesita una precisión significativa de entrada de datos para alcanzarlos.
El método de Tsai obtiene un parámetro de cámara preciso si los datos de entrada están ligeramente contaminados con estimación de ruido. Teniendo en cuenta que se necesitan al menos un centenar de puntos en la plantilla y las coordenadas debe ser referido de manera fija a las coordenadas del origen, además de la orientación y la posición de la cámara con referencia a los ejes de coordenadas, estos parámetros son: Rx, Ry y Rz representan a ángulos de rotación entre los ejes de transformación absolutos y Tx, Ty y Tz son los componentes del vector de translación para la transformación entre los ejes de la cámara y las coordenadas del sistema absoluto.
Adicionalmente, cinco parámetros intrínsecos relacionados con las constantes de la cámara que se sabe son necesarios, porque no es suficiente con mirar la información que el fabricante proporciona y que la cámara debe suministrar. Estos otros parámetros constantes son:
NCX, número de elementos sensores en la dirección horizontal; Nfx, el número de pixeles en la dirección horizontal de la cámara; dx, anchura de cada parte del sensor de la cámara (mm = el); dy, alta de cada elemento del sensor de la cámara (mm = el); dpx, anchura efectiva de un pixel en la cámara (mm/pix); dpy, altura efectiva de un pixel en la cámara (mm/pix).
La plantilla 3D consiste de dos o tres planos ortogonales entre sí, lo que conduce a una tarea laboriosa y costosa para llevar a cabo, teniendo en cuenta que es esencial para el diseño adecuado de la calibración, así como una medición exacta de las coordenadas de los puntos, para obtener buenos resultados al final del procedimiento. Sin embargo, la posibilidad de errores en las mediciones son altos. A continuación se presenta una imagen en 3D que muestra una plantilla que se utiliza para este método de calibración.

Imagen obtenida de https://www.frc.ri.cmu.edu/projects/mars/stereo.html Sólo para fines educativos
Método Zhang
Zhang propone una técnica de calibración basado en la observación de un blanco plano de varias posiciones. Este método utiliza las coordenadas de los puntos dentro de la plantilla plana en 2D tomando diferentes imágenes de la misma a partir de diferentes posiciones y orientaciones. Así, las ventajas de los métodos de calibración sobre la base de mediciones de las coordenadas de la plantilla con las ventajas de la autocalibración, en la que no es necesario el uso de una plantilla combinada. Este modo de calibración es muy flexible desde el punto de vista de la cámara y la plantilla se puede mover libremente y puede tomar tantas fotos como quieras sin tener que realizar mediciones en la plantilla.
La plantilla 2D no requiere una plantilla de diseño especial, ni como medición precisa de sus puntos. Por otra parte, el algoritmo de calibración de la sensibilidad a los errores en las mediciones se puede mejorar aumentando el número de puntos en la plantilla, simplemente imprimiendo un tablero de ajedrez con más esquinas.

Calibración automática.
Estas técnicas no utilizan objetos de calibración, ya que sólo es necesario relacionar un punto en diferentes imágenes. Sólo por mover la cámara en una escena estática la rigidez de la escena global provoca dos restricciones dentro de los parámetros de la cámara intrínseca. Por lo tanto, existen varias imágenes de la misma escena en los mismos parámetros intrínsecos, la correspondencia entre tres imágenes son suficientes para calcular tanto los parámetros intrínsecos y extrínsecos.
En estos casos incluso una plantilla no es necesaria, es necesario calcular un gran número de parámetros, lo que resulta en un complejo problema matemático. Debido a la dificultad para iniciar la búsqueda, los métodos de autocalibración tienden a ser inestables. Sería necesario considerar la familia de algoritmos que modelan los parámetros que el modelo de distorsión causada por la lente en la imagen sin necesidad de utilizar objetos de calibración, y por lo tanto, sin saber nada de la estructura 3D.
Estos métodos confían en que una proyección en perspectiva ideal permite que la cámara transforme líneas rectas en el espacio 3D en línea recta dentro del espacio de la imagen 2D correspondiente. Por este motivo, el refuerzo de la linealidad de las partes de las curvas de imagen son consecuencia de la distorsión de los lentes de la cámara, es posible determinar la deformación que está produce. Hay métodos que utilizan limitaciones epipolares y trilineales entre pares y tripletes de imágenes respectivamente para estimar la distorsión radial.
La elección de la calibración automática es debido a varias razones:
- Simplicidad de aplicación: sólo es necesario realizar múltiples capturas de un objeto familiar, de modo que varía su posición a través de una serie de fotografías.
- Validación de resultados: los datos obtenidos después de la calibración son tan buenos como los obtenidos con otros métodos, sin un alto costo computacional o equipos costosos requeridos.
Procedimiento de calibración.
Un paso esencial en la triangulación 3D con sistemas SL es su calibración, es decir, la determinación del interior de la orientación (distancia focal, posición del punto principal, parámetros de distorsión de la lente) del proyector de video y cámara digital, así como su posición relativa en el espacio (escala). Típicamente, una calibración de la cámara-proyector se lleva a cabo en dos pasos separados.
En primer lugar, la orientación interior de la cámara se estima, y el lado interior del proyector y orientación relativa son encontrados. En este contexto, utilice una superficie plana y una combinación de puntos de control circulares impresos y proyectando objetivos para realizar la calibración basada en el plano. Luego, usando la restricción epipolar, homologías entre el proyector y los píxeles de la cámara se establecen y el proyector se calibra. En la cámara se calibra y luego se realiza un escaneo completo de barrido SL de un objeto plano que contiene objetivos para obtener correspondencias entre el proyector y los píxeles de la cámara.
Este procedimiento se repite con diferentes orientaciones de la superficie plana, y sintetiza imágenes de las cuales el proyector podría calcular como una cámara virtual las cuales se calculan y se utilizan para su calibración. Finalmente, adopta la misma técnica de proyector de imágenes virtuales, a la vez que se propone un enfoque alternativo, en el cual una configuración calibrada de cámara con estéreo se utiliza para calcular las coordenadas 3D de un patrón proyectado en diferentes orientaciones del objeto plano; las coordenadas 3D adquiridas se utilizan en una etapa posterior de calibración del proyector.
Entonces, antes de la aplicación que permite el paso de calibración se ha requerido el uso de puntos en el tablero. Este objeto de calibración sigue un patrón simple de elipses negras, que permiten que el algoritmo funcione e identifique regiones con el software integrado.
1.6 Distancia de trabajo.
En visión estereoscópica, la distancia de trabajo para un punto en particular entre las imágenes obtenidas de dos cámaras es usada para calcular profundidad. Para ello es necesario que ambas cámaras estén debidamente alineadas, no sólo paralela una a la otra y a la línea entre ellas sino también coplanares, pero si la calibración no es buena se pierde precisión en la percepción de la profundidad.
Al identificar pares de puntos de cada imagen correspondientes al mismo lugar y la misma distancia (en pixeles) entre ellos, determina la profundidad con alta precisión. Un ejemplo es una cámara montada en una vía que puede moverse de un lado a otro. Hay una línea perpendicular a la vía, sin embargo, puede haber un ángulo de inclinación o una rotación de orientación. El eje de rotación es la línea perpendicular al plano formado por la línea de rotación de orientación y por la línea de rotación de ajuste.
Una cámara bien calibrada tendría α=β=0, es decir, tendría un eje de rotación perpendicular al plano de la vía. En el caso de dos cámaras, no sólo α y β equivalen a cero, sino también ץ . En visión por computadora es muy importante el concepto razón de longitud de píxel foco o longitud, o f/p, donde f es la distancia focal y p es la medida de cada pixel. La razón f/p relaciona los parámetros de la imagen formada dentro de las lentes y la imagen del mundo exterior.
Para finalizar, debemos saber que conocidas todas las partes de un objeto, llega el tiempo de determinar la selección del lente ideal para una aplicación disponible, utilizando las siguientes características para la correcta selección de la longitud del foco.
b= Tamaño del sensor CCD
B= Anchura del objeto
F = Distancia focal
D = Distancia de trabajo
C = Factor de conversión del tamaño del sensor
1.7 Manejo de patrones y marcas
El objetivo del aprendizaje de los sistemas de visión es programar a estos para que reconozcan objetos conocidos. El sistema almacena estos elementos en forma de compendio de valores da características extraídas que, a continuación, pueden compararse con los correspondientes valores de características obtenidos a partir de objetos desconocidos.
La principal aplicación de la visión artificial es para tareas automatizadas de inspección. Para aplicaciones de AIDC, los sistemas de visión artificial se utilizan para leer 2-D símbolos matriciales, como la matriz de datos, y también pueden ser utilizados para los códigos de barras apiladas, tales como PDF-417 (Las figuras se muestran en la sección 14.2, en el apartado de lectores de códigos de barras y 2D). Las aplicaciones de visión artificial también incluyen otros tipos de problemas de identificación automática, y estas aplicaciones pueden crecer en número a medida que avanza la tecnología. Por ejemplo, los sistemas de visión artificial son capaces de distinguir entre una variedad limitada de productos que se mueven por una cinta transportadora para que el producto se pueda clasificar. La tarea de reconocimiento se lleva a cabo sin necesidad de utilizar códigos de identificación especiales en los productos y en su lugar se basa en las características geométricas inherentes del objeto.
Los sistemas de visión se clasifican como 2D o 3D. Dos sistemas dimensionales ven la escena como una imagen 2D. Esto es muy adecuado para la mayoría de aplicaciones industriales, ya que muchas situaciones implican una escena 2D. Los ejemplos incluyen medición dimensional y de calibración, verificando la presencia de componentes, y la comprobación de las características de una superficie plana. Otras aplicaciones requieren un análisis 3D de la escena, y los sistemas de visión 3D son requeridos para este propósito.
La operación de un sistema de visión puede ser dividido en las tres categorías siguientes:
- Adquisición y digitalización de imágenes.
- Procesamiento de imágenes y análisis.
- Interpretación.
A continuación este proceso se muestra en la siguiente figura:
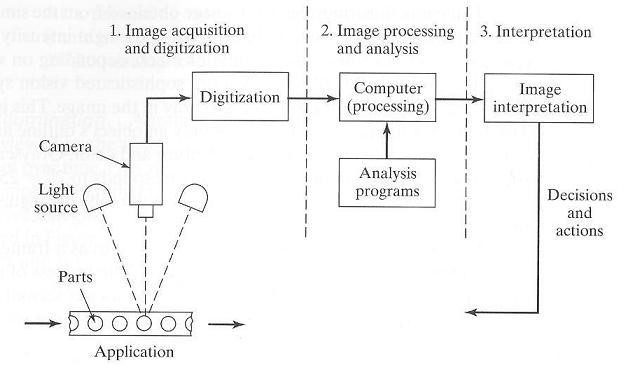
Fuente: Groover, M. (2015). Automation, Production System and Computer Integrated Manufacturing. (4a ed.). EE. UU.: Pearson.
Patrones en los códigos de barras.
En los códigos de barras se utilizan patrones de barras y espacios codificados que representan caracteres alfanuméricos o números. Comúnmente se usa la analogía de que los códigos de barras pueden ser tomados como una versión impresa de la clave Morse, donde las bandas estrechas representan puntos y las bandas anchas representan guiones. Usando este esquema, el código de barras para la familiar señal de desastre SOS se puede representar como se muestra en la siguiente figura:

Imagen tomada de Groover, M (2015). Automation, Production System and Computer Integrated Manufacturing. 4a ed. USA: Pearson. Solo para fines educativos
Los códigos de barras no siguen un código en clave morse, aun así, las dificultades de un código de barras en clave Morse en la interpretación de su simbología son: (1) sólo las barras oscuras son utilizadas, esto incrementa la longitud de los símbolos a codificar, y (2) el número de barras que componen los caracteres alfanuméricos difiere, haciendo la decodificación más complicada.
Marcas en los códigos de barras.
En varias aplicaciones de códigos de barras, las etiquetas son impresas en medianas a grandes cantidades para el empaque de productos y los cartones usados para el envío de productos empaquetados. Estos códigos de barras pre impresos son usualmente producidos fuera de sitio por compañías especializadas en estas operaciones. Las etiquetas son impresos en simbología idéntica o secuencial. Las tecnologías de impresión incluyen técnicas tradicionales como son la impresión de cartas, litografía e impresión flexográfica.
Los códigos de barras pueden ser impresos dentro de sitio por métodos en el cual los procesos son controlados por microprocesadores para archivar impresiones individualizadas del documento del código de barras o artículos etiquetados. Estas aplicaciones tienden a requerir múltiples impresoras distribuidas en locaciones donde pueden llegar a ser necesitadas. Las tecnologías de impresión usadas en estas aplicaciones incluyen:
Haz clic en cada concepto para ver a detalle.
Las barras de inyección de tinta están formadas por puntos de solapamiento, y los puntos se hacen a través de gotitas de tinta. Las ventajas recientes en la tecnología de inyección de tinta, motivadas por el mercado de las computadoras personales, han mejorado la resolución de impresión por chorro de tinta, y así son posibles los códigos de barras de alta densidad a un costo relativamente bajo.
En esta técnica las etiquetas de papel de color claro están recubiertas con una sustancia química sensible al calor que se oscurece cuando se calienta. La cabeza de impresión de la impresora térmica consiste en una serie lineal de elementos que calientan pequeñas áreas localizadas de la etiqueta mientras se mueve más allá de la cabeza, provocando que la imagen de código de barras deseado se forme. Los códigos de barras de impresión térmica directa son de buena calidad y el costo es bajo. Se debe tener cuidado con la etiqueta impresa para evitar la exposición prolongada a temperaturas elevadas ya la luz ultravioleta.
Esta tecnología es similar a la impresión térmica directa, excepto que la cabeza de impresión térmica está en contacto con una cinta de tinta especial que transfiere su tinta a la etiqueta en movimiento en áreas localizadas cuando se calienta. A diferencia de la impresión térmica directa, esta técnica puede utilizar papel normal (sin recubrimiento), por lo que la preocupación por la temperatura ambiente y la luz ultravioleta no aplican. La desventaja es que la cinta de tinta activado térmicamente se consume en el proceso de impresión y debe ser reemplazado periódicamente.
Es ampliamente utilizado en las impresoras para computadoras personales. En la impresión láser, la imagen de código de barras está escrito sobre una superficie fotosensible (tambor giratorio) por una fuente de luz controlable (el láser), formando una imagen electrostática en la superficie. La superficie se pone entonces en contacto con partículas de tóner que son atraídos a las regiones seleccionadas de la imagen. La imagen de tóner se transfiere a papel normal (la etiqueta) y es curado por calor y presión. Los códigos de barras de alta calidad se pueden imprimir mediante esta técnica.
Un proceso de grabado láser puede marcar los códigos de barras en las partes metálicas, proporcionando una marca de identificación permanente en el artículo que no es susceptible a daños en el duro ambiente s encontrado en muchas operaciones de fabricación. Otros procesos también se utilizan para formar tres códigos de barras bidimensionales permanentes en partes incluyen piezas de fundición, fundición, grabado y estampado. Un escaneo especial es requerido para leer estos códigos.
1.8 Lectores de códigos de barras y 2D.
Los lectores de códigos de barras vienen en una gran variedad de configuraciones, algunas requieren la presencia humana para operarse y otros funcionan como una sola unidad de manera automática. Usualmente son clasificados como lectores de contacto o sin contacto. Los lectores de códigos de barras de contacto son sujetos a mano con lápices ópticos operados moviendo la punta de la barra rápidamente más allá del código de barras en el objeto o documento. La punta de la barra debe estar en contacto con la superficie de código de barras o en proximidad muy cercana durante el procedimiento de lectura. En una aplicación de la recopilación de datos de fábrica, por lo general son parte de una terminal de entrada de teclado.
La terminal se refiere a veces como un objeto estacionario en el sentido de que se coloca en una ubicación fija en la empresa. Cuando se introduce una transacción en la empresa, los datos son comunicados por lo general al sistema de ordenador inmediatamente. Además de su uso en los sistemas de recogida de datos de fábrica, los lectores de códigos de barras de contacto estacionario son ampliamente utilizados en las tiendas minoristas para introducir el elemento en una transacción de venta.

Los lectores de códigos de barras de contacto también están disponibles como unidades portátiles que se pueden desplazar en torno a la fábrica o almacén por un trabajador. Utilizan la potencia de las baterías e incluyen un dispositivo de memoria de estado sólido capaz de almacenar los datos adquiridos durante la operación. Los datos pueden ser transferidos al sistema de ordenador posteriormente. Los lectores de códigos de barras portátiles a menudo incluyen un teclado que puede ser utilizado por el operador para introducir los datos de entrada que no se puede entrar a través de código de barras. Estas unidades portátiles se utilizan para la preparación de pedidos en un almacén y aplicaciones similares que requieren un trabajador se pueda mover distancias significativas en un edificio.
Los lectores de códigos de barras sin contacto centran un haz de luz sobre el código de barras, y un foto detector lee la señal reflejada para interpretar el código. La sonda de lectores se encuentra a una cierta distancia del código de barras durante el procedimiento de lectura. Los lectores sin contacto se clasifican como haz de luz fija y haz de luz en movimiento con escáner.
Los lectores de haz fijos son unidades fijas que utilizan un haz fijo de la luz. Se montan por lo general al lado de un transportador y dependen del movimiento del código de barras pasado el haz de luz para su funcionamiento. Las aplicaciones de lectores de códigos de barras de haz de luz fijo están típicamente en la operación de almacenamiento y manejo de materiales, donde grandes cantidades de materiales deben ser identificados a medida que fluyen pasado el escáner en transportadores. Los escáneres de haz de luz fijo en este tipo de operaciones representan algunas de las primeras aplicaciones de la industria de código de barras.

El traslado de los escáneres de haz de luz en movimiento utiliza un haz altamente concentrado de luz, a menudo un láser, accionado por un espejo giratorio que atraviesa un barrido angular en la búsqueda del código de barras en el objeto. Un escaneo se define como un solo barrido del haz de luz a través de una ruta angular. La alta velocidad de rotación del espejo permite muy altas velocidades de exploración. Arriba de 1440 escaneos por segundo. Esto significa que muchos escaneos con un único código de barras se pueden hacer durante un procedimiento de lectura típica, lo que permite la verificación de la lectura. El traslado de los escáneres de haz de luz pueden ser unidades ya sea fijos o portátiles. Los escáneres estacionarios están situados en una posición fija para leer los códigos de barras en los objetos a medida que se mueven más allá en un otro equipo de manejo de materiales o transportador. Se utilizan en los almacenes y centros de distribución para automatizar las operaciones de identificación del producto y su clasificación. Una configuración típica utilizando un escáner estacionario y se ilustra en la siguiente figura.
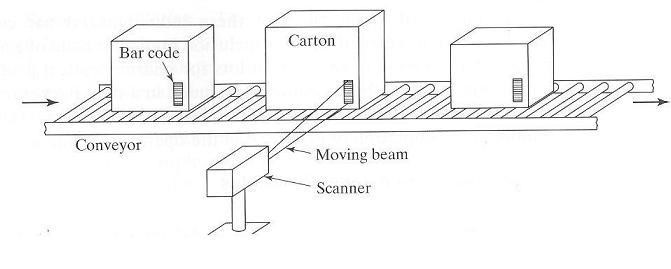
Imagen tomada de Groover, M (2015). Automation, Production System and Computer Integrated Manufacturing. 4a ed. USA: Pearson. Solo para fines educativos
Los escáneres portátiles son dispositivos de mano donde los puntos de los usuarios en el código de barras son como una pistola. La gran mayoría de los lectores de códigos de barras utilizados en fábricas y almacenes son de este tipo.
Códigos de barras en dos dimensiones (2D).
Los primeros códigos de barras en dos dimensiones (2D) fueron introducidos en 1987. Desde entonces, poco más de una docena de esquemas de símbolos en 2D han sido desarrollados, y el número tiene la expectativa de incrementarse. Los avances en los códigos 2D es su capacidad de almacenar mucha mayor cantidad de información en áreas de densidad mayores. Sus desventajas es que se requiere un equipo especial para leer los códigos, y el equipo es mucho más caro que los escáneres usados para los códigos de barras convencionales. Las simbologías en dos dimensiones se dividen dentro de dos tipos básicos: códigos de barras apilados y matriz de simbologías.
Haz clic en cada concepto para ver a detalle.
Códigos de barras apilados
El primer código de barras en 2D fue introducido con simbología de barras apiladas. Fue desarrollado en un esfuerzo para reducir el área requerida para un código de barras convencional. Pero su ventaja real es que puede contener significativamente grandes cantidades de información. Un código de barras apilado consiste en múltiples filas de códigos de barras convencionales lineales apilados sobre la cima de cada uno. Varios esquemas de apilados han sido desarrollados a lo largo de los años, todos muy cerca de las columnas múltiples permitidas y las variaciones en el número de caracteres codificados posible. La densidad de información de los códigos de barras apilados es típicamente cinco a siete veces más en comparación de un código de barras lineal clase 39. Un ejemplo del código de barras apilados se muestra en la siguiente figura:

Imagen tomada de Groover, M (2015). Automation, Production System and Computer Integrated Manufacturing. 4a ed. USA: Pearson. Solo para fines educativos
Simbología matriz
Una simbología matriz consiste de patrones 2D de celdas de información que son usualmente cuadradas y de color oscuro (usualmente negro) o blanco. La simbología de matriz fue introducida en 1990. Su ventaja sobre códigos de barras apilados es su capacidad de contener una mayor cantidad de información. Adicionalmente también cuentan con el potencial de una mayor densidad, arriba de 30 veces más denso que el código 39. Su desventaja comparada con los códigos de barras apilados es que estos son mucho más complicados y requieren equipo más sofisticado para impresión y lectura. Los símbolos deben ser producidos (durante la impresión) e interpretados (durante la lectura) tanto horizontal como verticalmente; por lo tanto, se refieren a veces como simbologías de la zona. un ejemplo de un código de matriz 2D se ilustran en la siguiente imagen:

Imagen tomada de Groover, M (2015). Automation, Production System and Computer Integrated Manufacturing. 4a ed. USA: Pearson. Solo para fines educativos
La lectura de un código de matriz de datos se utiliza para requerir un sistema de visión y una máquina sofisticada especialmente programado para la aplicación. Para hoy a los lectores de matriz de datos son mucho más fáciles de configurar y usar, y son más robustos, fiables que operan bajo una serie de condiciones. Las aplicaciones de las simbologías matriciales se encuentran en parte y la identificación del producto durante la fabricación y el montaje. La industria de semiconductores ha adoptado ECC200 Data Matrix (una variación del código de matriz de datos se muestra en la figura) como su estándar para el marcado y la identificación de obleas y otros componentes electrónicos.
1.9 Esquemas de iluminación
Otro aspecto importante de visión de máquina es la iluminación. La escena vista por la cámara visión debe estar bien iluminada y la iluminación debe ser constante en el tiempo. Esto casi siempre requiere que la iluminación especial se instalará para una aplicación de visión artificial en lugar de depender de la iluminación ambiental en la instalación.
Cinco categorías de iluminación se pueden distinguir de aplicaciones de visión artificial:
- luminación frontal.
- Iluminación de fondo.
- Iluminación lateral.
- Iluminación estructurada.
- Iluminación estroboscópica.
Se muestran a continuación en la siguiente imagen:

Imagen tomada de Groover, M (2015). Automation, Production System and Computer Integrated Manufacturing. 4a ed. USA: Pearson. Solo para fines educativos
Inspección de los sistemas de visión
Por el momento, la inspección de control de calidad es la categoría más grande. Instalaciones de visión artificial en la industria realizan una variedad de tareas de inspección automatizados, la mayoría de los cuales son ya sea en línea / postproceso. Las aplicaciones son casi siempre en la producción en masa, donde el tiempo necesario para programar y configurar el sistema de visión se puede transmitir durante muchos miles de unidades. La Inspección industrial típica incluye lo siguiente:
Medición dimensional |
Estas aplicaciones implican determinar el tamaño de ciertas características de dimensión de las piezas o productos usualmente en movimiento a velocidades relativamente altas sobre una cinta transportadora en movimiento. El sistema de visión artificial debe comparar las características (dimensiones) con las características correspondientes de un modelo por computadora almacena y determinar el valor de tamaño. |
Calibrado dimensional |
Esto es similar a la anterior, excepto que se realiza una función de calibración en lugar de una medición. |
Verificación de la presencia de componentes |
Está toma lugar en los productos ensamblados. |
Verificación de agujeros y localización del número de agujeros |
Operacionalmente, está tarea es similar a la medición dimensional y verificación de componentes. |
| Detección de superficies defectuosas y defectos |
Los defectos sobre la superficie de una parte o material siempre revelan por sí mismos un cambio en la luz reflejada. El sistema de visión es capaz de identificar la desviación desde un modelo ideal de la superficie. |
Detección de defectos en una etiqueta impresa |
El defecto puede estar en la forma de una etiqueta mal ubicado o texto mal impresos, numeración, o los gráficos en la etiqueta.
|
Todas las aplicaciones de inspección anteriores se pueden lograr sistemas de visión 2D usign. Ciertas aplicaciones requieren la visión 3D, como escanear el contorno de una superficie, la inspección de las herramientas de corte para comprobar si hay roturas y desgaste, y la comprobación de soldadura pasado los depósitos en la superficie de montaje en placas de circuito. Los sistemas tridimensionales están incrementando su uso en la industria automotriz para inspeccionar el contorno de superficies de componentes tales como paneles de la carrocería y bordes de los vehículos. La inspección con los sistemas de visión se puede lograr a velocidades mucho más altas que la inspección tradicional con MMC.






