2.1 Sistemas de iluminación
La iluminación es la parte más crítica dentro de un sistema de visión. Las cámaras capturan la luz reflejada de los objetos. El propósito de la iluminación utilizada en las aplicaciones de visión es controlar la forma en que la cámara verá el objeto. La luz se refleja de forma distinta si se ilumina una bola de boliche, que si se ilumina una hoja de papel blanco y el sistema de iluminación por lo tanto debe ajustarse al objeto a iluminar.
Hay un cierto número de consideraciones a tener en cuenta para determinar la mejor iluminación para una aplicación:
- ¿Es en color o monocromático?
- ¿Es de alta velocidad o no?
- ¿Cuál es el campo de visión a iluminar?
- ¿El objeto presenta superficies con reflejos?
- ¿Qué fondo presenta la aplicación: color, geometría?
- ¿Cuál es la característica a resaltar?
- ¿Qué duración debe tener el sistema de iluminación?
- ¿Qué requisitos ambientales deben considerarse?
Una buena iluminación de la escena es importante debido a su efecto sobre el nivel de complejidad de los algoritmos de procesamiento de imágenes requerido. Una iluminación deficiente hace más difícil la tarea de interpretar la escena. Las técnicas de iluminación adecuadas deben proporcionar un alto contraste y reducir al mínimo las reflexiones espectaculares y las sombras, a no ser que se diseñe específicamente en el sistema. Los tipos básicos de dispositivos de iluminación utilizados en la visión de máquina pueden agruparse en las categorías siguientes:
Haz clic para revisar la información
1. Iluminación mediante fibra óptica
Proporciona una gran intensidad de luz uniforme, con ausencia de sombras. Es ideal para iluminar objetos de reducidas dimensiones y se puede sujetar al objetivo de la cámara o a la óptica de un microscopio. Se les puede acoplar filtros de colores, polarizadores/analizadores y difusores para eliminar reflejos y aumentar el efecto difusor.
2. Iluminación mediante fluorescentes
Este tipo de iluminación proporciona una luz brillante, sin sombras. Las lámparas han sido diseñadas para suministrar el máximo de intensidad durante al menos 7 000 horas. Lo que proporciona una mayor productividad. Esta iluminación se aplica en entornos que requieren mucha luz, y ningún tipo de sombra (inspección de circuitos, laboratorios, control de calidad, fotografía, robótica, etc.).
4. Iluminación mediante láser
Los patrones láser se utilizan mayoritariamente en aplicaciones de medida de profundidad, y de superficies irregulares. Mediante ópticas especialmente diseñadas, se puede convertir un puntero láser, en diferentes formas y tamaños.
Varias técnicas de iluminación han sido desarrolladas para utilizar estos dispositivos de iluminación. La finalidad de estas técnicas es dirigir el recorrido de la luz desde el dispositivo de iluminación a la cámara, de modo que visualicen el sujeto de una manera adecuada para la cámara.
Hay dos técnicas básicas de iluminación utilizadas en la visión de máquina: iluminación frontal e iluminación posterior.
- La iluminación frontal significa simplemente que la fuente de luz está en el mismo lado de la escena que la cámara. En consecuencia, la luz reflejada se utiliza para crear la imagen visionada por la cámara.
- En la iluminación posterior la fuente de luz está dirigida a la cámara y situada detrás de los objetos de interés.
La imagen vista por la cámara es una silueta del objeto bajo estudio. La iluminación posterior es adecuada para aplicaciones en la que una silueta del objeto es suficiente para su reconocimiento o en donde exista la necesidad de obtener medidas importantes. A continuación se presenta una tabla, la cual indica otras técnicas diversas que pueden utilizarse para proporcionar iluminación.
Técnica |
Función/uso |
A. Fuente de luz frontal
- Iluminación frontal
- Iluminación especular (campo oscuro)
- Dispositivo formador de imágenes frontal
|
- Área iluminada de modo que la superficie defina la característica de imagen.
- Utilizada para el reconocimiento de defectos superficiales (fondo oscuro o luz de fondo).
- Aplicaciones de luz estructurada: la luz de las imágenes se superpone sobre la superficie del objeto.
|
B. Fuente de luz posterior
- Iluminación posterior (campo iluminado)
- Iluminación posterior (condensador)
- Iluminación desplazada posterior
|
- Utiliza un difusor superficial para las características de siluetas; se emplea en la inspección de piezas y medidas básicas.
- Produce imágenes de alto contraste; de utilidad para aplicaciones de gran ampliación.
- De utilidad para obtener imágenes destacadas cuando la característica está en un medio transparente.
|
C. Otros dispositivos misceláneos
- Divisor de haz
- Espejo dividido
- Redirectores no selectivos
- Retrorreflector
- Doble densidad
|
- Transmite luz a lo largo del mismo eje óptico del sensor; puede iluminar objetos de difícil visión.
- Similar al divisor de haz, con exigencias de intensidades más bajas.
- La fuente de luz se redirecciona para proporcionar una iluminación adecuada.
- Dispositivo que redirige los rayos incidentes hacia el sensor.
- Una técnica utilizada para aumentar la intensidad de iluminación en el sensor.
|
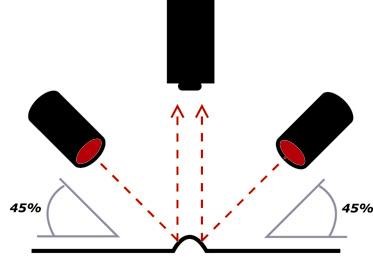
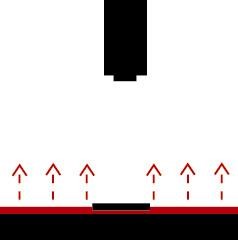
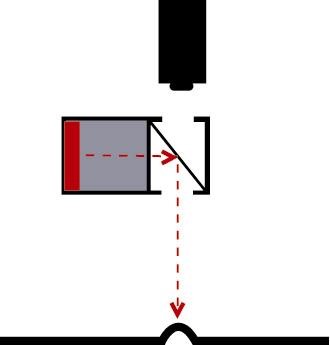
Para conseguir un campo de iluminación brillante, se requiere posicionar la cámara y la fuente de luz en posiciones específicas, tal como se indica en las siguientes figuras:
|
|
|
Fuente de luz frontal
(campo oscuro) |
Fuente de luz posterior |
Retrorreflector (misceláneo) |
2.2 Comparación de señal análoga contra la señal digital
Para una cámara que utiliza la tecnología de tubo vidicón es necesario convertir la señal analógica correspondiente a cada píxel a una forma digital. El proceso de conversión analógico/digital (A/D) implica la entrada de una señal de entrada analógica y la generación de una salida que represente la señal de voltaje en la memoria digital de una computadora.
Al realizar la conversión A/D y D/A aparecen errores y se tiene una parte de información de la señal continúa original. La conversión (A/D) está constituida por tres fases:
Haz clic para revisar la información
Proceso por el cual se obtiene una serie de muestras a partir de una señal continua. El tiempo de adquisición entre muestras se conoce como periodo de muestreo; en la mayor parte de las aplicaciones este tiempo es constante.
Una señal analógica dada se muestra periódicamente para obtener una serie de señales analógicas de tiempos discretos. Tal como se ilustra a continuación en la figura:
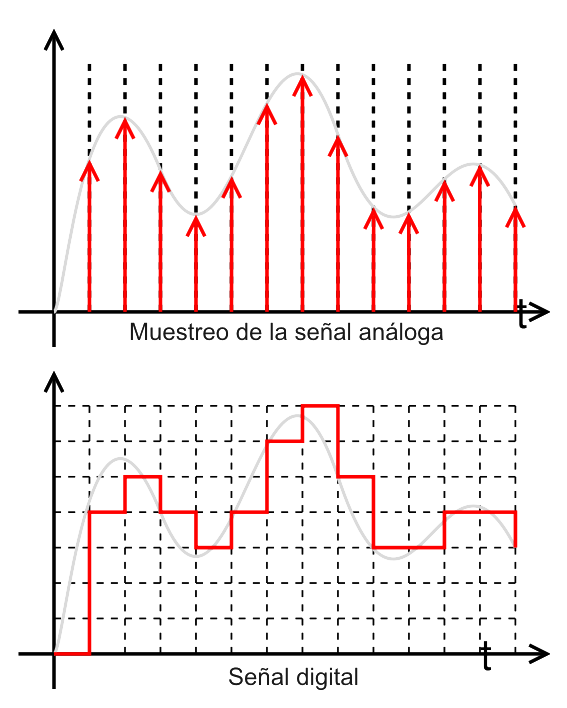
Groover, M., Weiss, M., Nagael, R. y Odrey, N. (1995). Industrial Robotics Technology, Programming and Applications. EE. UU: McGraw Hill.
Estableciendo una frecuencia de muestreo especificada, la señal analógica puede aproximarse mediante las salidas digitales muestreadas. El grado de aproximación de la señal analógica se determina por la frecuencia de muestreo del convertidor A/D. La frecuencia de muestreo debe ser al menos el doble que la más alta frecuencia de la señal de video, si se requiere reconstruir con exactitud dicha señal.
Después de muestrear se considera necesario cuantificar la señal. Cada nivel de voltaje de tiempo discreto muestreado se asigna a un número finito de niveles de amplitud definido. Estos niveles de amplitud corresponden a la escala de grises utilizada en el sistema. Los niveles de amplitud predefinidos son característicos para un convertidor A/D particular y están constituidos por un conjunto de valores discretos de niveles de voltaje. El número de niveles de cuantificación se define por:
Número de niveles de cuantificación = 2n
En donde n es el número de bits del convertidor A/D. Un gran número de bits permite que una señal se represente con más precisión. Por ejemplo, un convertidor de 8 bits nos permitiría cuantificar en 28 = 256 valores diferentes, mientras que 4 bits permitirían solamente 24 = 16 niveles de cuantificación diferentes.
Los niveles digitales son el equivalente a los niveles de cuantificación. El rango dinámico es la diferencia entre los niveles máximo y mínimo de x(n). Cuando se sobrepasa el rango del conversor, se tiene el ruido de sobrecarga.
Al cuantificar la señal se comete un error conocido, evidentemente, como error de cuantificación, que es irreversible. Se introduce ruido a la señal que se conoce como ruido de cuantificación.
Los niveles de amplitud que se cuantifican deben cambiarse al código digital. Este proceso, denominado codificación, implica la representación de un nivel de amplitud mediante una secuencia de dígitos binarios. La capacidad del proceso de codificación para distinguir entre varios niveles de amplitud es una función del espaciamiento de cada nivel de cuantificación. Dado el rango de escala completa de una señal de video analógico, el espaciamiento de cada nivel se definiría por:
| Espaciamiento nivel cuantificación: |

|
El error de cuantificación resultante del proceso de cuantificación puede definirse como:
Error cuantificación: ± ½ (espaciamiento nivel cuantificación)
Ejemplo: Una señal de vídeo continua ha de convertirse en una señal discreta. El rango de amplificación de la señal es de 0 a 5 volts. El convertidor A/D tiene una capacidad de 8 bits. Determinar el número de niveles de cuantificación, el espaciamiento del nivel de cuantificación, la resolución y el error de cuantificación.
Solución: Para una capacidad de 8 bits, el número de niveles de cuantificación es 28 = 256. La resolución del convertidor A/D es 1/256 = .0039 o 0.39%. Para el rango de 5V se tiene:
Espaciamiento nivel cuantificación: (5V)/(28 ) = .0195 Volts
Error cuantificación: ± ½ (.0195 Volts) = .00975 Volts
La representación de la señal de voltaje en forma binaria implica el proceso de codificación. Este último se realiza asignando la secuencia de dígitos binarios para representar niveles de cuantificación crecientes. En nuestro ejemplo anterior, la señal de voltaje puede indicarse de forma binaria. De los 8 bits disponibles podemos utilizar estos bits para representar niveles de cuantificación crecientes como sigue:
Rango de Voltaje, Volts |
Número binario |
Escala de grises |
0-.0195 Volts |
0000 0000 |
0 (negro) |
.0195-.0390 Volts |
0000 0001 |
1 (gris oscuro) |
.0390-.0585 Volts |
0000 0010 |
2 |
-------------------------------- |
-------------------------------------- |
------------------------------------ |
4.9610-4.9805 Volts |
1111 1110 |
254 (gris claro) |
4.9805-5.0 Volts |
1111 1111 |
255 (blanco) |
Después de la conversión A/D, la imagen se almacena en la memoria de la computadora, que suele denominarse un buffer de cuadro. Este buffer puede ser parte del captador de trama o estar en la propia computadora. Varias técnicas se desarrollaron para adquirir y acceder a las imágenes digitales. En condiciones ideales sería deseable adquirir un cuadro único de datos en tiempo real. El captador de trama es un ejemplo de un dispositivo de adquisición de datos de video que almacenará una imagen digitalizada y la adquirirá en 1/30 segundos. Los cuadros digitales suelen cuantificarse en 8 bits por píxel. Sin embargo, un buffer es apropiado puesto que el sistema de cámara medio no puede producir 8 bits de datos exentos de ruido. Por consiguiente, los bits de peso más bajo se eliminan como un medio de limpieza de ruido.
Además, el ojo humano sólo puede resolver (separar) unos 26 = 64 niveles de gris. Una combinación de contadores de filas y columnas se utiliza en el captador de trama, que se sincronizan con la exploración del haz electrónico de la cámara. De este modo, cada posición en la pantalla puede direccionarse de forma unívoca. Para leer la información almacenada en el buffer de trama, los datos se captan mediante una señal enviada desde la computadora a la dirección correspondiente a una combinación de fila-columna. Dichas técnicas de captador de trama se han hecho muy populares en la mayoría de los sistemas de visión.
Con base en lo anterior, es posible determinar las características, así como las ventajas y desventajas de una imagen digital en comparación de una imagen analógica, tal como se muestra en la siguiente tabla comparativa:
Características |
Almacenamiento Analógico |
Almacenamiento Digital |
Capacidad de almacenamiento |
Compromiso entre la amplitud de la señal y la frecuencia máxima almacenada. Dificultad en escribir transiciones rápidas/lentas sin destellos molestos. |
La frecuencia máxima almacenada es independiente de la amplitud. El modo de envolvente permite detectar glitches a cualquier velocidad de barrido. |
| Ancho de Banda |
Fijo, determinado por la respuesta del amplificador o velocidad de escritura.
Fijo, determinado por la respuesta del amplificador o velocidad de escritura. |
Variable, determinado por la velocidad de digitalización TIME/DIV.
El solapamiento crea señales falsas; los impulsos estrechos no se almacenan. |
| Problemas al superar el ancho de banda |
| Resolución |
Uniforme, verticalmente limitada por el perfil del punto, Horizontalmente limitada por la altura de la traza.
Las características de error son independientes de la señal de entrada; la atenuación debida a la limitación de banda, linealidad, etc., puede medirse y utilizarse para mejorar la precisión de la medida. |
Resolución vertical cuantificada; resolución horizontal limitada por el tamaño de memoria y el tipo de reconstrucción de la presentación. |
Errores de medida
|
Las características del error dependen de la relación de temporización entre la señal de entrada y el reloj de muestreo; los errores máximos son del mismo orden que los de los sistemas analógicos, pero las características de error no permiten su utilización para mejorar la precisión. |
2.3 Velocidad de captura
La velocidad de muestreo expresada en función de la frecuencia (20 x 106 muestras por segundo), equivale a decir que la velocidad de muestreo es de 20 MHz. A veces se cita la velocidad de información, es decir, el número de bits de datos almacenados en un segundo (160 millones de bits por segundo).
Para efectuar la conversión entre ambos valores basta con dividir la velocidad de la información entre el número de bits utilizado por el conversor A/D (en este caso, suponiendo un conversor de 8 bits, sería 160 x 106 bits dividido entre 8, lo que es igual a 20 x 106 muestras por segundo). En otras ocasiones, se expresa en función del intervalo de muestreo, como una relación tiempo/ puntos (50 ns por punto), el inverso de la frecuencia.
Para determinar la velocidad de digitalización para una determinada posición del mando TIME/DIV, se emplea la fórmula:
| Velocidad de digitalización = |

|
El número de palabras de datos por división es:
| Palabras de datos por visión = |

|
Indica la rapidez con la que un osciloscopio adquiere formas de onda completas.
Un DPO permite un nivel superior de observación del comportamiento de la señal, proporcionando velocidades de captura de forma de onda mucho más grandes y una presentación tridimensional, convirtiéndose en la mejor herramienta de diagnóstico y localización de fallos en diseños de tipo general para un amplio rango de aplicaciones.
2.4 Binarización de una imagen
Esta técnica también se conoce como fijación de umbrales. Consiste en una conversión binaria en la que cada píxel es convertido en un valor binario, blanco o negro. Estos toman valores entre 0 (negro) y 255 (blanco). Esto se consigue manipulando en forma adecuada los niveles de gris de la imagen (en una imagen en escala de grises.)
Para efectuar el procedimiento anterior, se realiza mediante la utilización de un histograma de frecuencias de la imagen y estableciendo qué intensidad (nivel de gris) será el límite entre el blanco y el negro. Como ejemplo, a continuación se muestra la imagen digital del rostro de una mujer:

Imagen tomada de http://www.uelbosque.edu.co/sites/default/files/publicaciones/revistas/revista_tecnologia/volumen3_numero2/fundamentos_procesamiento_digital_imagenes3-2.pdf Sólo para fines educativos.
Los niveles de grises de esta imagen digital se pueden representar en un histograma como se aprecia en la siguiente gráfica (niveles de gris vs frecuencia). El histograma permite determinar si la digitalización de la imagen se realizó correctamente.

Histograma resultante de una imagen aplicando niveles de grises.
Para los histogramas que son bimodales (dos ejes) en su forma, cada uno de los picos del histograma representa al propio objeto o al segundo plano sobre el que el elemento se apoya. Puesto que tratamos de diferenciar el objeto y el segundo plano; el procedimiento consistirá en establecer un umbral (por norma general, entre dos picos) y en asignar, por ejemplo, un bit 1 al objeto y un bit 0 al segundo plano o fondo. El resultado de esta técnica de fijación de umbrales se muestra en la siguiente fotografía, que muestra la imagen binaria digitalizada.

Imagen tomada de http://www.uelbosque.edu.co/sites/default/files/publicaciones/revistas/revista_tecnologia/volumen3_numero2/fundamentos_procesamiento_digital_imagenes3-2.pdf Sólo para fines educativos.
Se eligió un valor de umbral T=150, de un valor entre 0 (negro) y 255 (blanco). Lo cual dio como resultado la imagen. En la cual se diferencia el objeto de fondo. Para mejorar la capacidad de diferenciación, se debe aplicar las técnicas especiales de iluminación para generar un elevado contraste.
Cabe señalar que el método anterior del uso de un histograma para determinar un umbral es sólo uno del gran número de métodos existentes para definir una imagen. Sin embargo, es el método que utilizan actualmente algunos de los sistemas de visión de robot disponibles en el mercado. Se dice que dicho método utiliza un umbral tipo global para la imagen completa. En algunos casos esto no es posible y un método de fijación de umbral local puede ser utilizado.
Cuando no es posible encontrar un umbral simple para una imagen completa (por ejemplo, si mucho niveles distintos ocupan la misma escena y cada uno presenta niveles diferentes de intensidad), un método consiste en dividir la imagen total en áreas rectangulares más pequeñas y determinar el umbral para cada una de las ventanas que se analizan.
La fijación de umbrales es la técnica utilizada con más frecuencia para la binarización en aplicaciones de visión industriales. Las razones son que es más rápida y más fácil de llevar a cabo y que la iluminación se suele controlar en un establecimiento industrial. Una vez que se establece una fijación de umbrales para una imagen particular, el próximo paso es identificar las áreas particulares asociadas con los objetos dentro de la imagen. Dichas regiones suelen tener propiedades de pixeles uniformes calculadas sobre el área. Las propiedades de pixeles pueden ser multidimensionales, es decir, puede haber más de un atributo simple que puede utilizarse para caracterizar el píxel (color e intensidad de luz). Evitaremos esa complicación y limitaremos nuestro examen a los atributos de pixeles simples (intensidad de luz) de una región.

Crecimiento de región. Es un conjunto de técnicas en las que los pixeles se agrupan en regiones llamadas elementos de cuadrícula basadas en similitudes de atributos. Las regiones definidas se podrán examinar en cuanto si son independientes o se pueden fusionar a otras regiones por medio de un análisis de la diferencia en sus propiedades medias y su conectividad espacial.
Para diferenciar entre los objetos y el segundo plano, se asigna un 1 a cualquiera de los elementos de la cuadrícula ocupado por un objeto, y 0 a los elementos del segundo plano. Es práctica usual utilizar una retícula de muestreo cuadrada con pixeles igualmente espaciados a lo largo de cada uno de los lados de la cuadrícula.
Esta técnica de creación de pasadas de 1 y 0 se utiliza con frecuencia como un análisis de primer paso para la división de la imagen en segmentos identificables o “burbujas“. Observe que este procedimiento simple no identificó el agujero en la llave. Esto se resolvería disminuyendo la distancia entre los puntos de la cuadrícula e incrementando la exactitud con la que se representa la imagen original.
Para una imagen simple tal como una mancha oscura sobre un fondo claro, una técnica de pasadas puede proporcionar una información útil. Para imágenes más complejas, esta técnica puede no proporcionar una división adecuada de una imagen en un conjunto de regiones significativas. Dichas regiones podrían contener pixeles que estén conectados entre sí y teniendo atributos similares, por ejemplo, el nivel de gris. Una técnica típica de crecimiento de región para imágenes complejas podría tener el procedimiento siguiente:
- Seleccionar un píxel que cumpla con un criterio para la inclusión en una región.
El caso más simple sería seleccionar un píxel blanco y asignar un valor 1.
- Comparar el píxel seleccionado con todos los pixeles adyacentes. Asignar a los pixeles adyacentes un valor equivalente sí se produce una concordancia de los atributos.
- Ir a un píxel adyacente equivalente y repetir el proceso hasta que no se pueda añadir ningún píxel equivalente más a la región.
Este procedimiento simple de crecer regiones alrededor de un píxel se repetiría hasta que ninguna nueva región pueda añadirse a la imagen.
La técnica de segmentación de crecimiento de región aquí descrita es aplicable cuando las imágenes no son distinguibles entre sí mediante las técnicas de fijación de umbrales o detección de aristas. Esto se produce algunas veces cuando la iluminación de la escena no puede controlarse de forma adecuada. En los sistemas de visión de robots industriales es una práctica común considerar únicamente la detección de aristas o la fijación de umbral simple. Esto se debe al hecho de que la iluminación puede ser un factor controlable en un establecimiento industrial y es más sencilla la implementación de cómputo o de hardware.
2.5 Detección de aristas
Este procedimiento es una parte fundamental del procesamiento de imágenes y por lo tanto de la visión artificial. Es en esta etapa donde se delimitan todos los objetos de una escena que posteriormente son llevados a una etapa de reconocimiento. Como su nombre lo indica, en esta parte se busca extraer de la imagen las aristas o bordes de los objetos y para este fin es necesario tener presente que en dichos bordes se tiene un cambio brusco de los niveles de gris.
Esta técnica considera el cambio de intensidad que se produce en los pixeles en el contorno o borde de un objeto. Dado que se ha encontrado una región con atributos similares, pero se desconoce la forma del contorno, este último se puede determinar mediante un simple procedimiento de seguimiento de borde.
Para la detección de las aristas, el procedimiento es el de explorar la imagen hasta que se encuentre un píxel dentro de la región. Una vez encontrado un píxel en el interior de una región, torcer a la izquierda y avanzar o al contrario, tocar a la derecha y avanzar un paso. El procedimiento se detiene cuando se atraviesa el contorno y el camino vuelve al píxel inicial. El procedimiento de seguimiento del contorno descrito se puede extender a imágenes de nivel de gris.
Si retomamos la imagen del rostro de mujer y le aplicamos la técnica de detección de aristas, la imagen se mostraría de la siguiente forma.

Imagen obtenida de http://www.uelbosque.edu.co/sites/default/files/publicaciones/revistas/revista_tecnologia/volumen3_numero2/fundamentos_procesamiento_digital_imagenes3-2.pdf Sólo para fines educativos.
2.6 Detección de patrones
En las aplicaciones de sistemas de visión, con frecuencia es necesario distinguir un objeto de otro. Esto se suele realizar mediante el rastreo de patrones que caracterizan unívocamente al objeto. Entre algunas de las características de los objetos que pueden utilizarse en la visión de máquina se incluyen el área, el diámetro y el perímetro. Una característica, en el contexto de los sistemas de visión, es un parámetro único que permite la facilidad de comparación e identificación. Las técnicas disponibles para la extracción de valores de características para los casos bidimensionales se pueden categorizar aproximadamente como las que se refieren a las características de contorno y las que tratan las características de área. Los diversos patrones se pueden utilizar para identificar el objeto o parte del mismo y para determinar su localización u orientación.
A continuación se muestra una lista de algunas de las características utilizadas con más frecuencia en las aplicaciones de visión:
- Nivel de gris (máximo, medio, mínimo)
- Área.
- Longitud del perímetro
- Diámetro
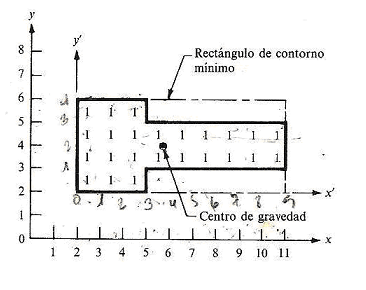
- Rectángulo de cierre mínimo
- Centro de gravedad. Para todos los píxel (n) en una región donde cada píxel está especificado por las coordenadas (x,y), las coordenadas x, y del centro de gravedad se definen por medio de las siguientes ecuaciones:

- Excentricidad: Una medida de elongación. Existen varias medidas de las cuales la más simple es:
Excentricidad = Longitud máxima de cuerda A/Longitud máxima de cuerda B
Donde la longitud máxima de cuerda B se mide perpendicular a A.
- Relación de aspecto: La relación longitud-anchura de un rectángulo de contorno que rodea el objeto. Un objetivo es encontrar el rectángulo que da la relación de aspecto mínima.
- Delgadez: Es la medida de lo delgado que es un objeto. Las definiciones que se utilizan son:
- Delgadez = (perímetro)2/área
- Delgadez = diámetro/área
El diámetro de un objeto, sin considerar su forma, es la distancia máxima obtenible entre dos puntos situados en el contorno de un objeto.
- Agujeros: Número de agujeros de un objeto.
- Momentos: Dada una región, R, y las coordenadas de los puntos (x,y) en o sobre el contorno de la región, el momento de orden del q-ésimo de la región viene dada por la siguiente expresión matemática.
Los procedimientos de crecimiento de región, descritos con anterioridad, se pueden utilizar para determinar el área de una imagen de un objeto. El perímetro o el contorno que encierra un área específica se puede determinar indicando la diferencia en la intensidad del píxel en el contorno y contando simplemente los pixeles de la región segmentada que son adyacentes a los pixeles que no pertenecen a la región; es decir, al otro lado del contorno. Un objetivo importante en la selección de estas características es que estás no dependa ni de la orientación ni de la posición. El sistema de visión no debe depender del objeto que se presenta a la cámara con una relación conocida y fija.
Las medidas anteriores proporcionan algunos métodos básicos para analizar las imágenes en un plano de dos dimensiones. Algunas otras medidas existen también para casos tridimensionales. Para ilustrar algunas de las definiciones y medidas en dos dimensiones se proporciona el siguiente ejemplo.
2.7 Identificación de patrones
El próximo paso en el procesamiento de los datos de la imagen es identificar el objeto que la imagen representa. Este problema de identificación se resuelve utilizando la información sobre las características extraídas del objeto. El algoritmo de reconocimiento debe ser lo suficientemente potente para identificar unívocamente al objeto. Las técnicas de reconocimiento de objeto utilizadas hoy en día en la industria se pueden clasificar dentro de dos características principales:
Haz clic en cada botón para obtener más información
Las técnicas de coincidencia de plantilla son un subconjunto de las técnicas estadísticas más generales de reconocimiento de modelos, que sirven para clasificar los objetos en una imagen dentro de las categorías predeterminadas. El problema básico de la coincidencia de plantilla es comparar el elemento con un conjunto de características del modelo almacenado, definido como modelo de plantilla. Este último modelo se obtiene durante el procedimiento de adiestramiento en el que el sistema de visión se programa para reconocer los elementos prototipos conocidos. Estas técnicas son aplicables si no existen requerimientos para un gran número de plantillas de modelos. El procedimiento está basado en el uso de un número suficiente de características para minimizar la frecuencia de errores en el proceso de clasificación. Las características del elemento en la imagen (por ejemplo, su área, diámetro, relación de aspecto, etc.) se comparan con los valores correspondientes almacenados. Estos valores constituyen la plantilla almacenada. Cuando se encuentra una coincidencia, permitiéndose determinadas variaciones estadísticas en el proceso de comparación, entonces el elemento ha sido clasificado de forma adecuada.
Las técnicas estructurales de reconocimiento de modelos consideran las relaciones entre las características o bordes de un objeto. Por ejemplo, si la imagen de un objeto se puede subdividir en cuatro líneas (las líneas reciben el nombre de primitivas) conectadas en sus puntos extremos y las líneas conectadas forman ángulos rectos, entonces el objeto es un rectángulo. Esta clase de técnica, conocida como reconocimiento de modelo sintáctico, es la técnica estructural usada con más frecuencia. Las técnicas estructurales difieren de las técnicas de decisión teórica, en que estas últimas tratan a un modelo sobre una base cuantitativa y en que se ignoran la mayoría de las interrelaciones de partes entre las primitivas de un objeto.
Puede considerarse excesivo el tiempo necesario para el reconocimiento completo de un modelo. En consecuencia, suele ser más adecuado en la búsqueda de regiones más simples o bordes dentro de una imagen. Estas regiones más simples pueden utilizarse para extraer las características requeridas. La mayor parte de los sistemas comerciales de visión hacen uso de este método para el reconocimiento de los objetos bidimensionales. Los algoritmos de reconocimiento se utilizan para identificar cada uno de los objetos segmentados en una imagen y para asignarlos a una clasificación (por ejemplo, tuerca, perno, brida, etc.).
Luz estructurada
El término luz estructurada se define como la proyección de patrones de luz simple o codificada (es decir, puntos, líneas, redes, formas complejas) en la escena iluminada. El principal beneficio de utilizar la luz estructurada es que las funciones de las imágenes tienen mejor definición. Como resultado, tanto la detección y extracción de características de la imagen es simplificada y más robusta.
En cuanto al dispositivo de emisión de luz, puede ser coherente (por ejemplo, los diodos láser) o incoherente (por ejemplo, dispositivos de cristal líquido (LCD) proyectores). El uso de proyectores LCD en sistemas estéreo activos puede ser rastreado desde principios de los 80. Estos sistemas se han vuelto muy populares, entre los trabajos de investigación, gracias a su atractivo costo y menos restricciones de seguridad en comparación con sus dispositivos basados en láser. Por otro lado, los proyectores para sistemas estéreo activos pueden ser la mejor opción para aplicaciones industriales. Estos sistemas, a menudo llamados escáner gama, se utilizan comúnmente en aplicaciones de robótica. A diferencia de los sistemas basados en LCD, los sistemas basados en láser pueden ser más pequeños y dar mayor potencia de iluminación. Además, gracias a su coherente característica, la cámara puede estar equipada con filtro óptico especial para mejorar tanto la detección y extracción de características de la imagen. Los patrones de luz proyectados se pueden agrupar en tres categorías: los patrones de punto, patrones de rayas y patrones de color. La posición, la orientación y las formas de los patrones de luz pueden ser alteradas o dejar sin cambios durante el proceso de escaneado.
Identificación de patrones por rayas |
Identificación de patrones de color |
Identificación de patrones por punto. |
El patrón geométrico simple de esta categoría, es la proyección de un solo rayo de luz o un plano en la escena. La intersección de este patrón de luz con la superficie de cualquier objeto en la escena produce una franja de luz visible en imágenes capturadas. Esta técnica supera a la técnica basada en patrones por punto como un conjunto más amplio de medidas en 3D, puede ser obtenida a partir de una sola imagen. Una vez más, con el fin de reducir el número de imágenes capturadas varias franjas de luz pueden proyectarse sobre la escena al mismo tiempo. Sin embargo, para estos sistemas, el problema de correspondencia está lejos de ser trivial. Para hacer frente a este problema, un patrón de rayas codificado puede ser utilizado. En efecto, mediante el llamado enfoque temporal con código de luz la correspondencia se puede resolver directamente como cada punto iluminado en la superficie de cualquier objeto en la escena se asocia con un código binario único. Como resultado, cada punto puede ser distinguido únicamente de sus vecinos adyacentes. |
Un inconveniente de los sistemas de estéreo activos utilizando patrones de rayas codificados es que la adquisición de imágenes es secuencial dependiendo del código generado. Como resultado, sólo escenas estáticas se pueden escanear con tales sistemas. Para superar esta situación, el uso de patrones de rayas estáticas o incluso patrones de color es obligatorio. De hecho, la información de color puede ser utilizado para etiquetar cada plano de luz del patrón proyectado.
Esta técnica permite recoger mediciones en 3D densas a partir de una sola imagen. Tales proyectos activos un sistema estéreo de color patrones de bandas que se pueden arreglar, ya sea en patrones paralelos o de cuadrícula. Por otra parte, a fin de obtener flexibilidad durante el proceso de adquisición de adaptación, las técnicas de color pueden utilizarse. Estos sistemas estéreo activos pueden adaptar el color del patrón proyectado para abordar el problema de las reflexiones de la luz generada por el objeto escaneado. |
Un sistema estéreo activo que proyecta un patrón de puntos es el método más sencillo para medir distancias entre la plataforma y los puntos de la superficie de los objetos analizados. El problema es la correspondencia de hecho es trivial. Sin embargo, sólo una medida puede ser obtenida de una sola posición ya sea del proyector, la cámara o la plataforma. Como resultado, toda la escena que se debe digitalizar para recoger mediciones 3D densas. A fin de aumentar medición de valores de una sola imagen, varias obras proponen proyectar varios puntos ya sea dispuesto en línea o en una rejilla de patrones. |
Aprendizaje de los sistemas de visión
El objetivo del aprendizaje de los sistemas de visión es programar a estos para que reconozcan objetos conocidos. El sistema almacena estos elementos en forma de compendio de valores da características extraídas que, a continuación, pueden compararse con los correspondientes valores de características obtenidos a partir de objetos desconocidos. Las características utilizadas con más frecuencia en los sistemas de visión se examinaron en el tema 8 en el punto 8.3 detección de patrones.
La identificación de patrones de los sistemas de visión debe realizarse bajo condiciones tan próximas a las condiciones de funcionamiento como fuere posible. Los parámetros físicos tales como emplazamiento de la cámara, ajustes de la apertura, situación del elemento e iluminación son las condiciones críticas que deben simularse como posibles durante el aprendizaje.
El esquema del sistema de visión para la interpretación de objetos, idealmente debe de quedar de la forma como se ilustra en la figura. Tomando en consideración la importancia de la calibración de la máquina, para completar el ciclo del sistema de visión, la cual se explicará detalladamente en el siguiente tema.
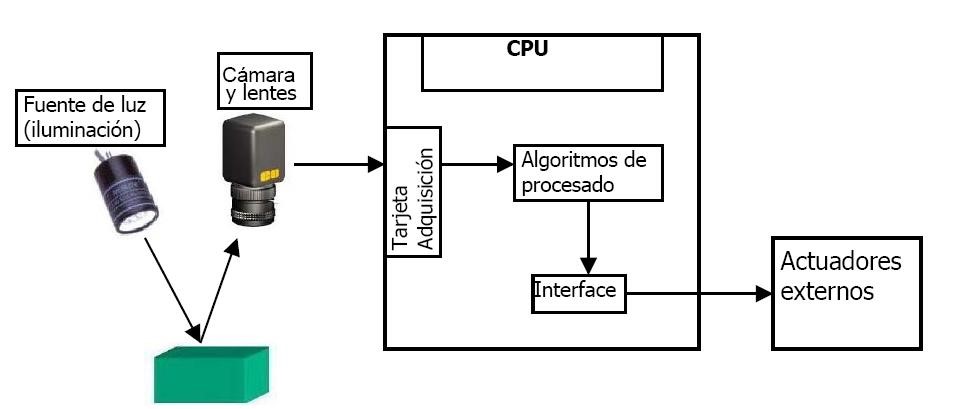
Imagen tomada de http://formacion.faico.org/Proyectos/ROBINDUSTRIA/SistemasDeVisionArtificial.htm
Sólo para fines educativos.
2.8 Identificación de fallas
La falla más común que se produce en la interpretación de imágenes y que es necesario tomar en cuenta son las distorsiones, estás se producen durante la formación de imágenes.
Distorsión radial
El uso de lentes facilita la entrada de la luz, un apropiado enfoque y la versatilidad adecuada, pero también introduce distorsiones en las imágenes formadas en el sensor. Uno de estos efectos es la distorsión radial o distorsión de barril, y se muestra esquemáticamente en la siguiente figura. Esta distorsión es debido a las lentes de rayos que pasan más lejos del centro óptico, las cuales afectan la incidencia de aquellos que directamente pasan cerca del centro de la lente.
Este tipo de distorsión es más pronunciada en la zona cercana a los límites de las imágenes, como se puede ver en el ejemplo de abajo. Es importante señalar que también crece con la disminución de longitud focal de la lente utilizada o cuando más pobre se utiliza la óptica de calidad.

Imagen obtenida de http://www.cipa.dcu.ie/roadis/dis.html. Solo para fines educativos.
Distorsión tangencial
Puede ser que durante el proceso de manufactura, el sensor está conectado firmemente a la pared sobre la que descansa. De esta manera la lente no será utilizado paralela al plano donde la imagen se forma.
2.9 Reconstrucción en 3D
La reconstrucción 3D es el proceso por el cual los objetos son escaneados en un sistema de coordenadas X, Y, Z, utilizando una codificación por el método de la agrimensura, manteniendo las características físicas del objeto (tamaño, volumen y forma). Por lo tanto, se emplea un procedimiento de calibración o los parámetros del sistema, convierte la secuencia de imágenes adquiridas y procesadas digitalmente, a la escala completa del objeto. Por esta razón, los métodos de reconstrucción 3D son una herramienta útil en aplicaciones en las que la información topográfica juega un papel importante en la toma de decisiones; como para el control de calidad, el modelado 3D de objetos industriales y exploraciones funcionales de deformación en la espalda o en otras partes del cuerpo, entre otros.
En este tema se mostrarán los métodos básicos como la técnica de luz estructurada para la medición de superficies en 3D para su aplicación. Métodos de codificación se utilizan para resolver el problema de la correspondencia entre los puntos proyectados en una superficie y el punto en el plano de la imagen en el plano del sensor se enfatizan. El principio general en el que los sistemas se basan de luz estructurada para obtener información tridimensional en medir superficies se basa en el método de triangulación.
El desarrollo para un sistema de visión 3D requiere la solución de una serie de aspectos o etapas: la recuperación de la estructura tridimensional de la escena, el modelado y el objeto de representación, el reconocimiento y la localización, y la interpretación de la escena. Las diferentes técnicas para recuperar la estructura tridimensional de la escena tienen características específicas en todos los niveles del proceso de interpretación visual, desde las imágenes iniciales, el análisis y la interpretación de la misma, todos los métodos requieren equipos específicos para la solución de algoritmos.
Triangulación y luz estructurada.
Dentro del campo de visión tridimensional, hay una serie de técnicas que actualmente se utilizan con éxito en numerosas aplicaciones industriales. Entre ellas, la que se conoce como luz estructurada. Este tipo de sistema se caracteriza por un método directo y activo. Un método directo se caracteriza porque las conclusiones se pueden obtener mediante el análisis de los datos obtenidos directamente de las imágenes. En cuanto al método activo, se tiene en cuenta que este sistema utiliza un sistema generador de luz, lo que introduce un tipo de energía con el medio ambiente en el que se realizó el estudio.
El sistema de luz estructurada se basa en el estudio de la deformación de un patrón de luz para ser interceptado por cualquier objeto. Este es el principal problema con este tipo de herramientas que se necesita un tipo de luz concentrada en un punto. Como este podría no encontrarse iluminado, cualquiera de los sistemas usuales que se utilizan actualmente, tales como bombilla, focos fluorescentes, etc., están compuestos por ondas de diferentes frecuencias causando que el rayo de luz sea utilizado a través del medio ambiente.
Una de las mejores soluciones es utilizar un rayo láser. Debido a sus características de la coherencia, la divergencia y de direccionamiento, se comporta en una luz perfecta para dichos sistemas. Esto es debido a que la consistencia hace que todas las ondas tengan la misma frecuencia, y con su pequeña divergencia y alta directivita permiten que se dirija un rayo láser en cualquier punto que se desee. Una vez que usted y el tipo de luz que se utilizará es conocido, es necesario elegir un modelo adecuado. Las diferentes soluciones que van desde el uso de rejillas con puntos de láser de diferentes colores. La contratación de puntos significa tener para atravesar el objeto a través de la superficie de tomar una gran cantidad de puntos y algunas áreas pueden perderse.
El uso de un plano parece una solución mejor que la anterior. El plano ilumina un conjunto de puntos con las mismas características y cumplen con la condición de un plano en el espacio. Utilizar una cuadrícula con diferentes puntos de color envueltos implica que tiene toda la superficie del objeto iluminado y una vez que el problema es encontrado, se buscan los diferentes puntos y situaciones. Por supuesto, además del patrón de luz, necesita una cámara que recoge todas las imágenes de la deformación del plano del láser. La posición de la cámara en el conjunto debe ser uno, lo que permite obtener tanto la mejor resolución como prevenir las áreas oscuras, es decir, no hay zonas del objeto que no están iluminadas por el láser.
Una vez que se haya decidido sobre uno u otro patrón y la cámara correspondiente tendrá que calibrar los diferentes parámetros. Este paso es el más importante como para las coordenadas de diferentes puntos en el objeto es emplear el método de triangulación. El método de triangulación se utiliza para obtener la posición de un punto con relación a la posición de la cámara y el plano. La siguiente figura explica el esquema del método de triangulación:
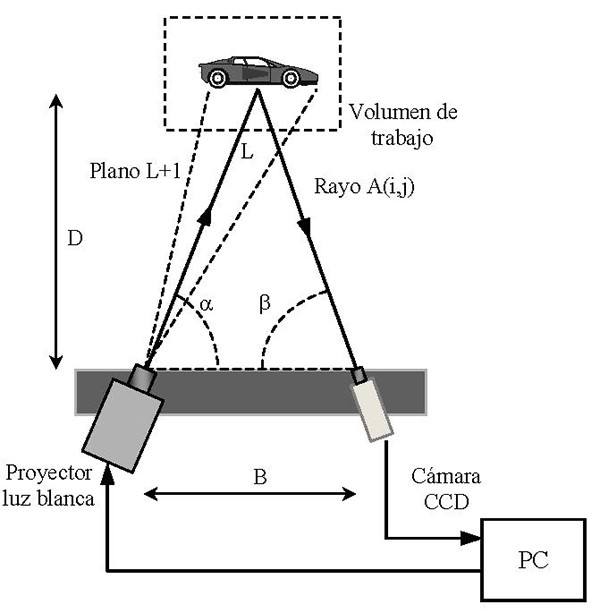
Imagen obtenida de http://www.e-medida.es/documentos/Numero-3/control_dimensional_tecnologia_luz_blanca_celdas_inspeccion Sólo para fines educativos.
Si se conoce la distancia de la cámara a un punto de objeto, que es la base del triángulo, la distancia entre la cámara y el láser, un lado, y el ángulo del plano del láser, podemos ver las coordenadas tridimensionales de ese punto. Pero para ello es necesario conocer las posiciones en el espacio tanto de la cámara y el plano de láser, por lo que será es necesario, un proceso de calibración en ambos sistemas. Los patrones proyectados están diseñados de manera que cada píxel de la imagen se le puede asignar un código bien definido. La proyección de Técnicas de tales patrones pueden ser de clasificación de acuerdo a la estrategia de codificación utilizado, divididos en tres grupos:
- Tiempo de multiplexación técnica
- Técnicas espaciales de vecindad
- Codificación directa
En nuestro caso consideramos sólo el tiempo de las llamadas técnicas multiplexados uno de los más extendidos en sistemas comerciales para la exploración de luz estructurada en tres dimensiones. Entre las técnicas de multiplexación una de las más importantes es la siguiente:
Patrones de nivel de gris binarios y codificación técnica.
La codificación binaria utiliza rayas blanco y negro para formar una secuencia de patrones de proyección, de modo que cada punto de la superficie del objeto tiene un código binario único, el cual difiere de cualquier otro código en diferentes puntos. En general, los patrones de rayas pueden codificarse con 2n.