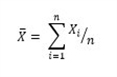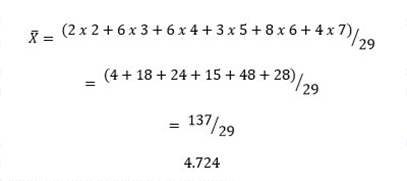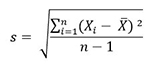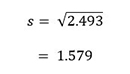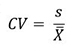Distribución de frecuencias, tabulación cruzada y prueba de hipótesis
Una vez finalizado el paso anterior y con los datos listos y totalmente preparados para su análisis, el investigador puede dar comienzo a los análisis estadísticos básicos.
En este tema se describirán estos, iniciando con la distribución de frecuencias en las que se analizan los datos a profundidad de manera independiente, esto es, variable por variable. Posteriormente, veremos tabulaciones cruzadas, en las que una misma variable puede ser separada para su análisis o combinada con una o dos variables adicionales para profundizar en los hallazgos. Cerramos el tema con las pruebas de hipótesis paramétricas y no paramétricas, basadas en una o dos muestras.
12.1 Distribución de frecuencias
El proceso de análisis de datos siempre debe iniciarse atendiendo a responder peguntas sobre una sola variable. Las respuestas a este tipo de preguntas se dan a través de las distribuciones de frecuencias, mismas que consideran una variable a la vez. Su objetivo es obtener un conteo del número de respuestas relacionadas con los distintos valores que obtuvo cada variable. Esto es, una distribución de frecuencias de una variable produce una tabla de conteo de frecuencias y porcentajes acumulados para todos los valores asociados con esa variable.
La siguiente tabla muestra los resultados de 30 entrevistas realizadas a personas a quienes se les realizaron preguntas sobre su apreciación de Internet. La tabla contiene el número de encuesta o folio, el sexo del entrevistado (1= hombre, 2 = mujer), su nivel de acuerdo con darle un uso positivo al Internet (la respuesta 1 marca un totalmente de acuerdo y la respuesta 7 un totalmente en desacuerdo), las horas a la semana que generalmente usa Internet, su actitud hacia el internet y la tecnología (ambas en 1 = muy poco favorable y 7 = muy favorable) y si han realizado compras o transacciones bancarias por internet (1 = sí, 2 = no). Las respuestas faltantes se marcaron con 9.
| Folio |
Sexo |
Uso + de internet |
Uso en horas de internet |
Actitud hacia Internet |
Actitud hacia tecnología |
Compras en Internet |
Transacciones bancarias en Internet |
Zona geográfica |
| 1 |
1 |
7 |
14 |
7 |
6 |
1 |
1 |
2 |
| 2 |
2 |
2 |
2 |
3 |
3 |
2 |
2 |
1 |
| 3 |
2 |
3 |
3 |
4 |
3 |
1 |
2 |
1 |
| 4 |
2 |
3 |
3 |
7 |
5 |
1 |
2 |
1 |
| 5 |
1 |
7 |
13 |
7 |
7 |
1 |
1 |
2 |
| 6 |
2 |
4 |
6 |
5 |
4 |
1 |
2 |
2 |
| 7 |
2 |
2 |
2 |
4 |
5 |
2 |
2 |
1 |
| 8 |
2 |
3 |
6 |
5 |
4 |
2 |
2 |
2 |
| 9 |
2 |
3 |
6 |
6 |
4 |
1 |
2 |
2 |
| 10 |
1 |
9 |
15 |
7 |
6 |
1 |
2 |
2 |
| 11 |
2 |
4 |
3 |
4 |
3 |
2 |
2 |
1 |
| 12 |
2 |
5 |
4 |
6 |
4 |
2 |
2 |
1 |
| 13 |
1 |
6 |
9 |
6 |
5 |
2 |
1 |
2 |
| 14 |
1 |
6 |
8 |
7 |
2 |
2 |
2 |
2 |
| 15 |
1 |
6 |
5 |
4 |
4 |
1 |
2 |
1 |
| 16 |
2 |
4 |
3 |
6 |
3 |
2 |
2 |
1 |
| 17 |
1 |
6 |
9 |
5 |
3 |
1 |
1 |
2 |
| 18 |
1 |
4 |
4 |
5 |
4 |
1 |
2 |
1 |
| 19 |
1 |
7 |
14 |
6 |
6 |
1 |
1 |
2 |
| 20 |
2 |
6 |
6 |
6 |
4 |
2 |
2 |
2 |
| 21 |
1 |
6 |
9 |
4 |
2 |
2 |
2 |
2 |
| 22 |
1 |
5 |
5 |
5 |
4 |
2 |
1 |
1 |
| 23 |
2 |
3 |
2 |
4 |
2 |
2 |
2 |
1 |
| 24 |
1 |
7 |
15 |
6 |
6 |
1 |
1 |
2 |
| 25 |
2 |
6 |
6 |
5 |
3 |
1 |
2 |
2 |
| 26 |
1 |
6 |
13 |
6 |
6 |
1 |
1 |
2 |
| 27 |
2 |
5 |
4 |
5 |
5 |
1 |
1 |
1 |
| 28 |
2 |
4 |
2 |
3 |
2 |
2 |
2 |
1 |
| 29 |
1 |
4 |
4 |
5 |
3 |
1 |
2 |
1 |
| 30 |
1 |
3 |
3 |
7 |
5 |
1 |
2 |
1 |
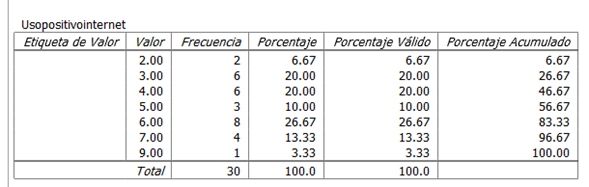
A partir de los datos anteriores, se desarrolló la siguiente tabla, únicamente considerando las respuestas a la variable Uso Positivo de Internet, en la que se resumen los resultados de las respuestas sobre el nivel de acuerdo acerca del uso positivo de Internet.
ETIQUETAS DE VALOR
| |
Valor |
Frecuencia |
Porcentaje |
Porcentaje Válido |
Porcentaje acumulado |
| TOTALMENTE DE ACUERDO |
1 |
0 |
0 |
0.0 |
0.0 |
| |
2 |
2 |
6.67 |
6.9 |
6.9 |
| |
3 |
6 |
20.00 |
20.7 |
27.6 |
| |
4 |
6 |
20.00 |
20.7 |
48.3 |
| |
5 |
3 |
10.00 |
10.3 |
58.6 |
| |
6 |
8 |
26.67 |
27.6 |
86.2 |
| TOTALMENTE EN DESACUERDO |
7 |
4 |
13.33 |
13.8 |
100.0 |
| |
9 |
1 |
3.33 |
|
|
| |
TOTAL |
30 |
100 |
100 |
|
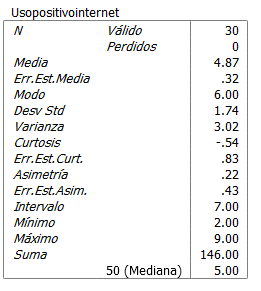
Una distribución de frecuencias ayuda a determinar la magnitud de la falta de respuestas a las preguntas. También indica la magnitud de respuestas ilegítimas o errores. Aquí se pueden identificar casos con estos valores y tomar medidas correctivas. También es posible detectar la presencia de datos o valores extremos.
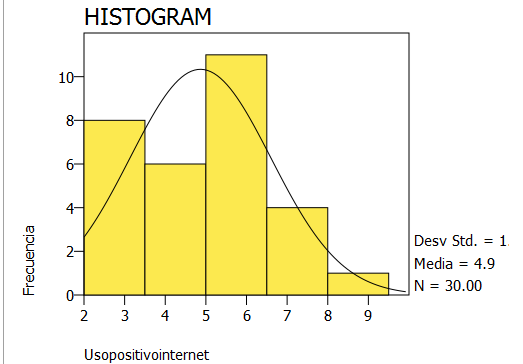
Una distribución de frecuencias indica, de manera empírica, la forma de la distribución de una variable. Estos datos con frecuencia se emplean para construir un histograma, que es una gráfica de barras vertical donde los valores de la variable se muestran a lo largo del eje X y las frecuencias absolutas o relativas se colocan en el eje Y. El siguiente gráfico es un ejemplo de histograma.
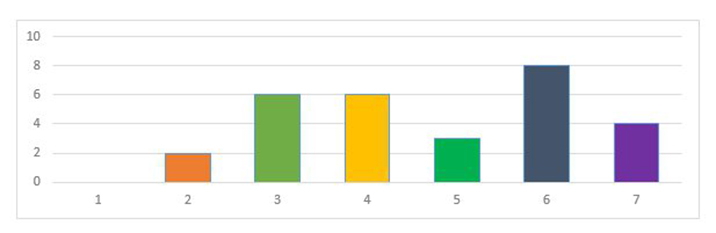
Así, la distribución de frecuencias es una manera muy conveniente y adecuada de analizar los distintos valores que puede tomar una variable. Las tablas de frecuencia son sencillas de leer y poseen información detallada. Sin embargo, existe otro tipo de estadísticas que se asocian a las mismas y que ayudan a resumirla, a través de estadísticos descriptivos. Los más utilizados son las medidas de localización, las de variación y las de forma.
Medidas de localización
Las más comunes y que veremos en este tema son las medidas de tendencia central que llevan ese nombre porque tienden a describir el centro de la distribución.
Haz clic en la imagen para conocer detalle de las medidas de localización
Medidas de variabilidad
Éstas se calculan con datos de intervalo o razón.
Haz clic en la imagen para conocer detalle de las medidas de variabilidad
Medidas de forma
Adicionales a las medidas de variación existen también medidas de forma que son útiles para entender la naturaleza de una distribución. La forma de la misma se determina a través de la asimetría y la curtosis.
Haz clic en la imagen para conocer detalle de las medidas de forma.
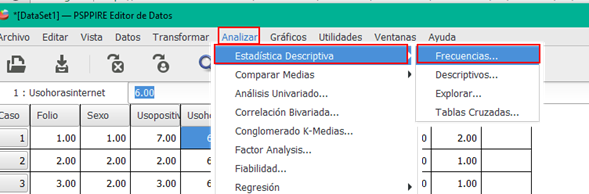
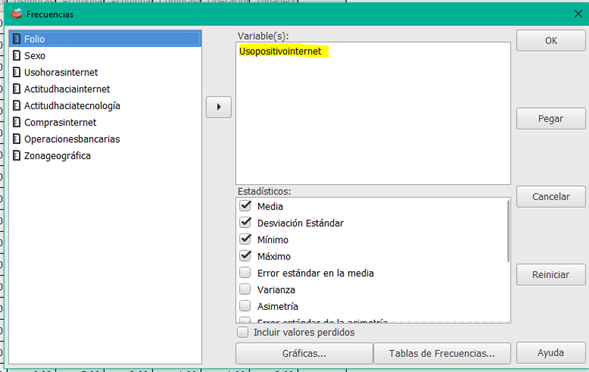
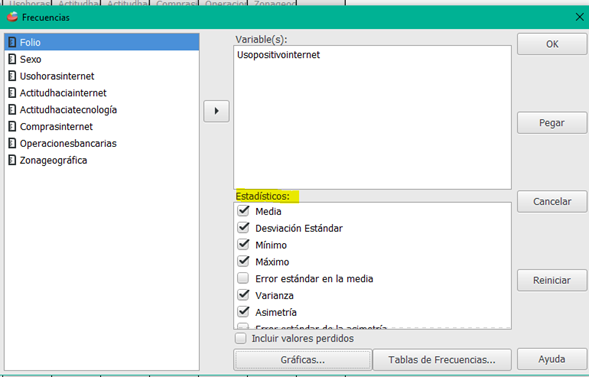
PSPP
El principal programa en PSPP es FREQUENCIES. Produce una tabla de conteos de frecuencias, porcentajes y porcentajes acumulativos para los valores de cada variable. Proporciona todos los estadísticos asociados.
Haz clic en la imagen para conocer detalle de PSPP.
12.2 Introducción a la prueba de hipótesis
Un análisis básico siempre implica alguna prueba de hipótesis. En temas anteriores, vimos los conceptos de la distribución de la muestra, el error estándar de la media o de la proporción, y el intervalo de confianza. Todos estos conceptos son importantes para la prueba de hipótesis y deben revisarse.
El procedimiento general para la prueba de hipótesis es el siguiente:
Haz clic en cada punto para conocer detalle de información
Paso 1: Formular las hipótesis nula y alternativa.
Una hipótesis nula es un enunciado sobre el status quo, sin diferencia o con ningún efecto. Si la hipótesis nula no se rechaza, no se realizan cambios. Una hipótesis alternativa es aquella en la que se espera cierta diferencia o efecto. Aceptar la hipótesis alternativa llevará a cambios en las opiniones o acciones.
La hipótesis nula es la que siempre se pone a prueba y se refiere a un valor específico del parámetro de la población (por ej., μ, σ, π) y no a un estadístico de muestra (por ejemplo, 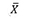 ). Una hipótesis nula puede rechazarse, pero nunca se acepta con base en una sola prueba. En la prueba de hipótesis clásica no hay forma de determinar si la hipótesis nula es verdadera.
). Una hipótesis nula puede rechazarse, pero nunca se acepta con base en una sola prueba. En la prueba de hipótesis clásica no hay forma de determinar si la hipótesis nula es verdadera.
En la investigación de mercados, la hipótesis nula se formula de tal manera que su rechazo lleva a la aceptación de la conclusión deseada. La hipótesis alternativa representa la conclusión para la cual se busca la evidencia. Continuando con la tabla ejemplo del principio, se podría pensar en implementar un servicio de compras por internet (tienda virtual) si más del 40% de los usuarios realizaran compras por este medio. Una forma de expresarlo podría ser:
H0 = π ≤ 0.40
H1 = π > 0.40
La prueba de la hipótesis nula es una prueba de una cola, porque la hipótesis alternativa se expresa de forma direccional. Si ese no es el caso, se necesitaría una prueba de dos colas, y las hipótesis se expresarían así, considerando acorde al ejemplo anterior, que la proporción de usuarios de Internet que compran por este medio difiere del 40%
H0 = π = 0.40
H1 = π ≠ 0.40
En la investigación de mercados se utiliza más la prueba de una cola que la de dos colas. Por lo general, existe una dirección preferida en la conclusión para la que se busca evidencia.

Paso 2: Elegir la prueba adecuada
Para probar la hipótesis nula, es necesario seleccionar una técnica estadística apropiada. Es importante considerar la forma en que se calcula el estadístico de la prueba y la distribución de la muestra de donde se deduce éste (p.ej., la media). El estadístico de pruebamide cuánto se aproxima la muestra a la hipótesis nula y generalmente se deduce de una distribución bien conocida, como la distribución normal t, o chi cuadrada.
En nuestro ejemplo, el estadístico z, que sigue a la distribución normal estándar, sería el apropiado.
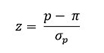
Donde:
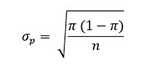

Paso 3: Seleccionar el nivel de significancia, 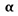
Cuando se realizan inferencias sobre la población a través de pruebas de hipótesis, siempre se corre el riesgo de incurrir en un error, esto es, tomar la decisión incorrecta.
El error tipo I ocurre cuando los resultados de la muestra conducen al rechazo de una hipótesis nula cuando en realidad es verdadera. La probabilidad del error del tipo I () también se denomina nivel de significancia. En el ejemplo de Internet, se cometería un error tipo I si, basándonos en los datos de la muestra, concluyéramos que la proporción de clientes que prefieren el nuevo plan de servicio fue mayor que 0.40, cuando en realidad fue menor o igual que 0.40.
El error tipo II ocurre cuando, basándonos en los resultados de la muestra, no se rechaza una hipótesis nula que en realidad es falsa. La probabilidad de un error de tipo II se denota con  . A diferencia de que el investigador marca, la magnitud de depende del valor real del parámetro (proporción) de la población. Continuando con el ejemplo, se cometería un error tipo II si, basándonos en los datos de la muestra, concluyéramos que la proporción de clientes que prefiere el nuevo plan de servicio es menor o igual que 0.40, cuando en realidad es mayor que 0.40
. A diferencia de que el investigador marca, la magnitud de depende del valor real del parámetro (proporción) de la población. Continuando con el ejemplo, se cometería un error tipo II si, basándonos en los datos de la muestra, concluyéramos que la proporción de clientes que prefiere el nuevo plan de servicio es menor o igual que 0.40, cuando en realidad es mayor que 0.40
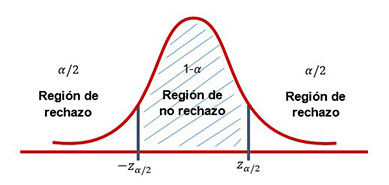
La potencia de una prueba es la probabilidad (1 - β) de rechazar una hipótesis nula cuando es falsa y que debe rechazarse. Aunque se desconoce β, ésta se relaciona con α. Un valor de extremadamente pequeño (por ejemplo, 0.001) producirá grandes errores intolerables. Así que es necesario equilibrar los dos tipos de errores.

Paso 4: Reunir los datos y calcular el estadístico de prueba
Al determinar el tamaño de la muestra se consideran los errores α y β. Se reúnen los datos requeridos y se calcula el valor del estadístico de prueba. Basándonos en el ejemplo de Internet, el valor de la proporción de la muestra = 17/30 = 0.567 (30 respondientes, 17 hacen compras por Internet).
El valor de σp se determina de la siguiente manera:
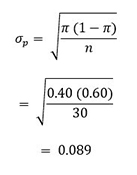
El estadístico z de prueba puede calcularse de la siguiente manera:


Paso 5: Determinar la probabilidad (valor crítico)
Usando las tablas normales estándar (distribución z), se puede calcular la probabilidad de obtener un valor z de 1.88. Esto se aprecia también en la siguiente figura:
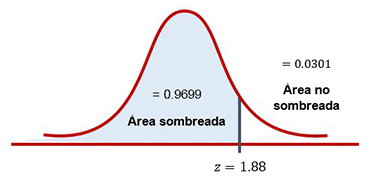
El área sombreada entre ∞ y 1.88 es 0.9699. Por lo tanto, el área a la derecha de z = 1.88 es 1.0000 - 0.9699 = 0.0301.
De manera alternativa, el valor crítico de z, que proporciona un área al lado derecho del valor crítico de 0.05, está entre 1.64 y 1.65 y es igual a 1.645.
Observe que para determinar el valor crítico del estadístico de prueba, el área a la derecha del valor crítico es α o ∝⁄2. Es para la prueba de una cola y ∝⁄2 para la prueba de las dos colas.

Pasos 6 y 7: Comparar la probabilidad (valor crítico) y tomar la decisión
Si la probabilidad asociada con el valor calculado u observado del estadístico de prueba EPcal es menor que el nivel de significancia α se rechaza la hipótesis nula. En el ejemplo, la probabilidad asociada con el valor calculado u observado del estadístico de prueba es 0.0301. Ésta es la probabilidad de obtener un valor p de 0.567 cuando π = 0.40. Este es menor que el nivel de significancia de 0.05. Por lo tanto, se rechaza la hipótesis nula.
De manera alternativa, si el valor calculado del estadístico de prueba es mayor que el valor crítico EPcr, se rechaza la hipótesis nula. Para el ejemplo, el valor calculado del estadístico de prueba z = 1.88 se ubica en la región de rechazo, más allá del valor de 1.645. Una vez más, se llega a la misma conclusión de rechazar la hipótesis nula.
Si observa con detenimiento, notará que las dos formas de comprobar la hipótesis nula son equivalentes pero matemáticamente opuestas de acuerdo en la dirección de la comparación. Si la probabilidad de EPcr < nivel de significancia α, entonces se rechaza H0, pero si EPcal > EPcr, entonces se rechaza H0.


Paso 8: Conclusión de la investigación de mercados
Para asentar o redactar una conclusión de investigación de mercados, ésta debe expresarse en términos del problema de investigación. En el ejemplo que hemos estado trabajando sobre las compras por Internet, podemos concluir que existe evidencia de que la proporción de usuarios de Internet que compra a través de este medio es significativamente mayor que 0.40. Así, se podría sugerir como recomendación a la tienda a la que pertenece dicha investigación de mercado que podría lanzar un nuevo servicio de compras por Internet.
La prueba de hipótesis puede relacionarse con el hecho de examinar asociaciones o diferencias. En las pruebas de asociaciones, la hipótesis nula plantea que no hay una relación entre las variables:
H0: ... NO está relacionada con...
En las pruebas de diferencias, la hipótesis nula afirma que no existen diferencias:
H0: ... NO difiere de...
Los distintos tipos de pruebas de hipótesis pueden verse en el siguiente diagrama de clasificación:
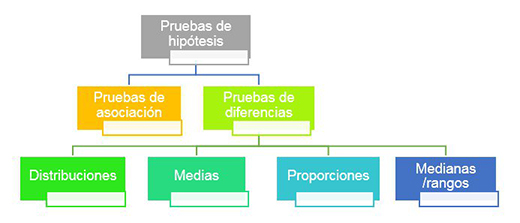
Las pruebas de diferencias se pueden relacionar con distribuciones, medias, proporciones, medianas o rangos. A continuación, analizaremos primeramente las hipótesis relacionadas con asociaciones en el contexto de las tabulaciones cruzadas.
12.3 Tabulaciones cruzadas

Lo que hemos visto hasta el momento, responde a cuestionamientos de variables por sí mismas es interesante, muy frecuentemente los investigadores se hacen otras preguntas sobre la relación entre esa variable y otras.
Al introducir la distribución de frecuencias planteamos varias preguntas de investigación de mercados. Mientras que una distribución de frecuencias describe una variable a la vez, una tabulación cruzada describe dos o más variables de forma simultánea. La tabulación cruzada produce tablas que reflejan la distribución conjunta de dos o más variables con un número limitado de categorías o valores distintos. Las categorías de una variable se cruzan con las categorías de otras variables. De esta manera, la distribución de frecuencias de una variable se subdivide conforme a los valores o las categorías de las otras variables.
Si continuamos con el ejemplo del inicio del tema, podemos tomar otras dos variables distintas para hacer una tabulación cruzada. Supongamos que queremos saber si el sexo está relacionado con el uso de Internet. Para lograrlo, ahora consideraremos el sexo de los entrevistados y los clasificaremos acorde a las horas de uso de Internet, considerando a quienes reportan usarlo 5 horas o menos como esporádicos y al resto como frecuentes. En la siguiente tabla podemos ver los resultados:
Sexo y uso de Internet
| |
Sexo |
|
| Uso de Internet |
Hombre |
Mujer |
Total |
| Esporádico (1) |
5 |
10 |
15 |
| Frecuente (2) |
10 |
5 |
15 |
| Total |
15 |
15 |
|
Aquí se observa que la tabulación cruzada incluye una celda para cada combinación de las categorías de las dos variables. El número en cada celda indica la cantidad de participantes que dio esa combinación de respuestas. Así, 10 participantes son mujeres que reportaron un uso esporádico de Internet. Los totales marginales de esta tabla indican que de los 30 participantes con respuestas válidas en ambas variables, 15 reportaron un uso esporádico y 15 un uso frecuente. En términos del sexo, 15 individuos son mujeres y 15 son hombres.
Toda la información descrita en el párrafo anterior podría haberse obtenido de una distribución de frecuencias separada para cada variable. Por ello, podemos decir que, al margen, una tabulación cruzada muestra la misma información que las tablas de frecuencias de cada variable. A las tablas de tabulación cruzada también se les conoce como tablas de contingencia. Se considera que los datos incluidos son cualitativos o categóricos, ya que se asume que cada variable sólo tiene una escala nominal.
TC de 2 variables
La tabulación cruzada con dos variables también se conoce como tabulación cruzada bivariada. En el ejemplo de sexo y uso de Internet, al ver las cantidades se observa una mayor cantidad de hombres que usan frecuentemente la Internet. Para apreciarlo adecuadamente, es factible trasladar las cantidades a porcentajes.
Debido a que se cruzaron dos variables, los porcentajes se calculan por columnas, con base en los totales de las columnas o por renglón, con base en los totales de renglón, como se aprecia en las siguientes dos tablas.
Sexo por uso de Internet
| |
Sexo |
| Uso de Internet |
Hombre |
Mujer |
| Esporádico (1) |
33.3% |
66.7% |
| Frecuente (2) |
66.7% |
33.3% |
| Total |
100.0% |
100.0% |
Uso de Internet por Sexo
| |
Uso de Internet |
|
| Sexo |
Esporádico (1) |
Frecuente (2) |
Total |
| Hombre |
33.3% |
66.7% |
100% |
| Mujer |
66.7% |
33.3% |
100% |
La regla general consiste en calcular los porcentajes en dirección de la variable independiente, por la variable dependiente. En el análisis de nuestro ejemplo, el sexo puede considerarse la variable independiente y el uso de Internet la variable dependiente, por lo que la primera tabla sería la forma correcta de presentar los resultados.
Basados en esto, se resume que mientras que el 66.7 % de los hombres son usuarios frecuentes, sólo el 33.3 % de las mujeres cae dentro de esta categoría. Esto parece indicar que los hombres tienen mayores posibilidades de ser usuarios frecuentes de Internet, en comparación con las mujeres.
Pero, ¿por qué no considerar que la segunda tabla sea adecuada? Si la analizamos, en este caso, los porcentajes calculados en la dirección de la variable dependiente por la variable independiente no tienen mucho sentido; implica que el uso frecuente de Internet causa que las personas sean hombres, lo cual no es muy creíble. Sin embargo, antes de descartar totalmente esta posibilidad, tal vez se requiera analizar más a detalle la asociación entre el uso de Internet y el sexo, sobre todo considerando una tercera variable, como la edad o el ingreso.
Haz clic para conocer detalle de la información
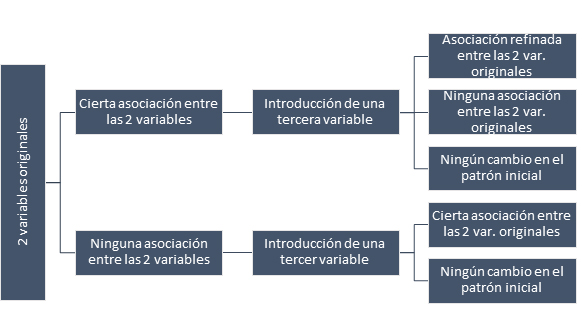
TC de 3 variables – Ausencia de cambio en la relación inicial
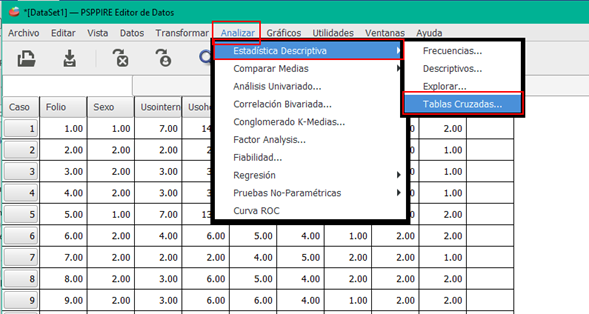
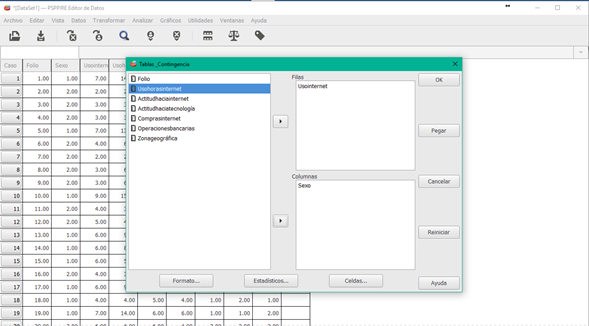
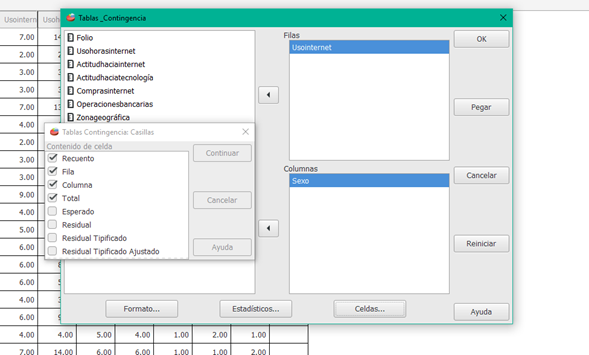
El principal programa para tabulaciones cruzadas es CROSSTABS. Este programa produce tablas de clasificación cruzada y ofrece conteos por celda, porcentajes por renglón y columna.
Haz clic en la imagen para conocer detalle del proceso
Estadísticos asociados con la tabulación cruzada
Una vez que hemos visto las tabulaciones cruzadas, podemos ahora analizar los estadísticos más utilizados para evaluar la significancia y fuerza estadística de la asociación de variables en tabulaciones cruzadas.
La significancia estadística de la asociación observada generalmente se mide usando el estadístico chi cuadrada. La fuerza de la asociación o el grado de relación es importante desde una perspectiva práctica o sustantiva. Por lo general, la fuerza de la asociación sólo nos interesa si ésta es estadísticamente significativa. La fuerza de la asociación se puede medir mediante el coeficiente de correlación fi, el coeficiente de contingencia, la V de Cramer y el coeficiente lambda.
Haz clic en cada punto para conocer información
Chi cuadrada
Este estadístico llamado chi cuadrada (χ2) se emplea para probar la significancia estadística de una asociación observada en la tabulación cruzada, ayudando a determinar si existe una relación sistemática entre dos variables. La hipótesis nula, H0, plantea que no hay una asociación entre las variables.
La prueba se realiza calculando las frecuencias que se esperaría observar en las celdas si no hubiera una asociación entre las variables, dados los totales por renglón y por columna. Estas frecuencias de celda esperadas, que se simbolizan fe, posteriormente se comparan con las frecuencias reales observadas, fo, para calcular el estadístico chi cuadrada. Entre más grande sean las discrepancias entre las frecuencias esperadas y las reales, mayor será el valor del estadístico.
Se asume que la tabulación cruzada tiene r renglones y c columnas, y una muestra aleatoria de n observaciones. Posteriormente, se calcula la frecuencia esperada de cada celda usando la siguiente fórmula:

Dónde:
nr = número total de renglones
nc = número total de columnas
n = número total de la muestra
Retomando el ejemplo de sexo y uso de internet, podemos calcular el estadístico chi cuadrada.
Sexo y uso de Internet
| |
Sexo |
|
| Uso de Internet |
Hombre |
Mujer |
Total |
| Esporádico (1) |
5 |
10 |
15 |
| Frecuente (2) |
10 |
5 |
15 |
| Total |
15 |
15 |
|
Con estos datos, realizamos los siguientes cálculos (izquierda a derecha y arriba hacia abajo):

Se continúa calculando el valor del estadístico:
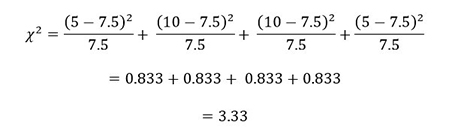
Con la intención de determinar si existe una asociación sistemática, se estima la probabilidad de obtener un valor de chi cuadrada, tan grande o más grande que el calculado a partir de la tabulación cruzada. Una característica importante de la chi cuadrada es el número de grados de libertad (gl) asociados a éste, es decir, gl= (r - 1) (c -1).
La hipótesis nula (H0) de que no hay relación entre las dos variables se rechaza únicamente cuando el valor calculado del estadístico de prueba es mayor que el valor crítico de la distribución chi cuadrada, con el número apropiado de grados de libertad, tal cual lo muestra la siguiente figura.
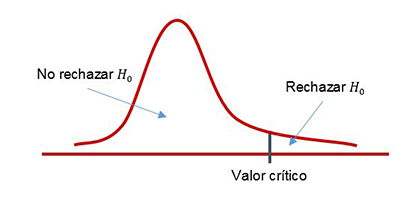
El estadístico chi cuadrada χ2 se utiliza para probar la significancia estadística de la asociación observada en una tabulación cruzada. Su distribución es asimétrica cuya forma depende únicamente del número de grados de libertad. Conforme este número de grados aumenta, la distribución chi cuadrada es más simétrica.
La mayoría de las tablas del estadístico chi cuadrada contienen áreas de la cola superior de esta distribución, para distintos grados de libertad. Si buscamos en la tabla, el valor que aparece en la parte superior de cada columna indica el área de la porción superior (el lado derecho, como se muestra en la figura anterior) de la distribución chi cuadrada. Por ejemplo, para 1 grado de libertad, el valor de un área de la cola superior de 0.05 es 3.841.
En la tabulación cruzada de la tabla del ejemplo de sexo y uso de internet existe (2-1) x (2-1) = 1 grado de libertad. El estadístico chi cuadrada calculado tuvo un valor de 3.333. Como esta cifra es menor que el valor crítico de 3.841, no puede rechazarse la hipótesis nula de no asociación, lo que indica que la relación no es significativa, desde el punto de vista estadístico, a un nivel de 0.05.
Es conveniente aclarar que la falta de significancia en este caso se debe principalmente al pequeño tamaño de la muestra (30). Si el tamaño de la muestra fuese de 300, y cada entrada de la tabla anterior se multiplicara por 10, se vería que el valor del estadístico chi cuadrada se multiplicaría por 10 y sería 33.33, que sí es significativo al nivel de 0.05.
Coeficiente fi
El coeficiente fi (Φ) es utilizado como una medida de la fuerza de la asociación en los casos especiales de tablas con dos renglones y dos columnas (tablas 2 x 2). El coeficiente fi es proporcional a la raíz cuadrada del estadístico chi cuadrada.
Toma el valor de 0 cuando no hay asociación, lo que también indicaría una chi cuadrada de 0. Cuando las variables están perfectamente relacionadas, fi toma un valor de 1 y todas las observaciones caen justo en la diagonal principal o secundaria.
Se calcula de la siguiente manera:
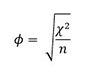
En el ejemplo que estamos manejando no es relevante calcularlo, ya que la chi cuadrada reveló una falta de asociación. Sin embargo, sólo para ejemplificarlo, se haría de la siguiente manera:

De esta manera, demostramos una asociación sumamente débil.
Para tablas mayores a 2 x 2, se utiliza el coeficiente de contingencia.
Coeficiente de contingencia
En tanto que el coeficiente fi es specífico para una tabla de 2 x 2, el coeficiente de contingencia C se utiliza para evaluar la fuerza de la asociación en una tabla de cualquier tamaño. Varía también entre 0 y 1, indicando con 0 la falta de asociación pero nunca alcanza el valor máximo de 1. Se calcula de la siguiente manera:
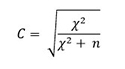
El valor máximo del coeficiente de contingencia depende del tamaño de la tabla (del número de renglones y de columnas). Por esta razón, sólo debe emplearse para comparar tablas del mismo tamaño.
En el ejemplo —aunque nuevamente no es relevante y se usa sólo con fines didácticos— se calcularía de la siguiente manera:

Indicando nuevamente que no es una relación fuerte.
Otro estadístico que se puede calcular es la V de Cramer.
V de Cramer
La V de Cramer es una versión modificada del coeficiente de correlación fi 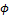 y se utiliza en tablas más grandes que las de 2 x 2.
y se utiliza en tablas más grandes que las de 2 x 2.
Al calcular fi para una tabla más grande que 2 x 2, no tiene un límite superior. La V de Cramer se obtiene al ajustar fi al número de renglones o al número de columnas de la tabla, dependiendo de cuál de los dos sea más pequeño. El ajuste es tal que V va del 0 al 1. Un valor grande de V sólo indica un alto grado de asociación, y no la forma en que las variables están relacionadas. Para una tabla con r renglones y c columnas, la relación entre la V de Cramer y el coeficiente de correlación fi se expresa de la siguiente manera:
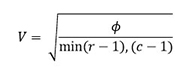
O lo que es lo mismo:
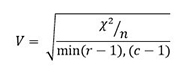
El valor de la V de Cramer del ejemplo de sexo y uso de Internet es:
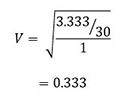
Así, continuamos con la misma conclusión: la asociación no es muy fuerte. Como observamos, en este caso V = ϕ. Esto ocurre siempre con una tabla de 2 x 2.
Otro estadístico que se calcula comúnmente es el coeficiente lambda.
Coeficiente lambda
La lambda asimétrica mide el porcentaje de mejoría para pronosticar el valor de la variable dependiente, dado el valor de la variable independiente. Es muy útil cuando las variables analizadas están en escala nominal.
Lambda también varía entre 0 y 1, siendo el valor de 0 una falta de mejora en el pronóstico, mientras que el 1 indica se puede predecir sin error. Esto sucede cuando cada categoría de la variable independiente está asociada con una sola categoría de la variable dependiente.
La lambda asimétrica se calcula para cada una de las variables (tratada como la variable dependiente).
También es posible calcular una lambda simétrica, que es un tipo de promedio de los dos valores asimétricos. La lambda simétrica no hace ninguna suposición sobre cuál variable es la dependiente. Mide la mejoría general cuando el pronóstico se realiza en ambas direcciones.
El valor de lambda asimétrica del ejemplo de sexo y uso de Internet, usada como la variable dependiente es 0.333. Esto indica que el hecho de conocer el sexo de la persona incrementa la posibilidad de predicción en una proporción de 0.333. En otras palabras, hay una mejoría del 33.3%. El valor de lambda simétrica también es 0.333.
Existen otros estadísticos, como tau b, tau c y gamma, para medir la asociación entre dos variables de nivel ordinal. Tanto tau b como tau c hacen ajustes para los empates.
Tau b es el más apropiado para tablas cuadradas, en las que son iguales el número de renglones y el de columnas. Su valor oscila entre +1 y -1.
Para una tabla rectangular en la que el número de renglones es diferente del número de columnas, se debe utilizar tau c.
Gamma no realiza ajustes para los empates ni para el tamaño de la tabla. Gamma también varía entre +1 y -1 y, por lo general, tiene un valor numérico más grande que tau b o tau c.
La tabulación cruzada en la práctica
Al llevar a cabo un análisis de tabulación cruzada es útil seguir estos pasos.
- Poner a prueba la hipótesis nula de que no existe una asociación entre las variables por medio del estadístico chi cuadrada. Si no se rechaza la hipótesis nula, no existe ninguna relación.
- Si se rechaza H0, se debe determinar la fuerza de la asociación utilizando un estadístico apropiado (coeficiente fi, coeficiente de contingencia, V de Cramer, coeficiente lambda u otro estadístico), según se analizaron anteriormente.
- Si se rechaza H0, debe interpretarse el patrón de la relación calculando los porcentajes en la dirección de la variable independiente, por la variable dependiente.
- Si se trata a las variables como ordinales más que como nominales, utilice tau b, tau c o gamma como estadístico de prueba. Si se rechaza H0, entonces determine la fuerza de la asociación utilizando la magnitud y la dirección de la relación con el signo del estadístico de prueba.
Aquí se continúa con el procedimiento de tabulación cruzada iniciado en el subtema anterior. Recordando:
Haz clic en la imagen para conocer detalle del proceso