Host-based Remote Replication
Host-based remote replication uses the host resources to perform and manage the replication operation. There are two basic approaches to host-based remote replication: Logical volume manager (LVM) based replication and database replication via log shipping.
LVM-based remote replication is performed and managed at the volume group level. Writes to the source volumes are transmitted to the remote host by the LVM. The LVM on the remote host receives the writes and commits them to the remote volume group. Prior to the start of replication, identical volume groups, logical volumes, and file systems are created at the source and target sites. Initial synchronization of data between the source and replica is performed. One method to perform initial synchronization is to backup the source data and restore the data to the remote replica. Alternatively, it can be performed by replicating over the IP network. Until the completion of the initial synchronization, production work on the source volumes is typically halted. After the initial synchronization, production work can be started on the source volumes and replication of data can be performed over an existing standard IP network. LVM-based remote replication supports both synchronous and asynchronous modes of replication. If a failure occurs at the source site, applications can be restarted on the remote host, using the data on the remote replicas.
LVM-based remote replication is independent of the storage arrays and therefore supports replication between heterogeneous storage arrays. Most operating systems are shipped with LVMs, so additional licenses and specialized hardware are not typically required. The replication process adds overhead on the host CPUs. CPU resources on the source host are shared between replication tasks and applications. This might cause performance degradation to the applications running on the host.
Database replication via log shipping is a host-based replication technology supported by most databases. Transactions to the source database are captured in logs, which are periodically transmitted by the source host to the remote host. The remote host receives the logs and applies them to the remote database. Prior to starting production work and replication of log files, all relevant components of the source database are replicated to the remote site. This is done while the source database is shut down.
After this step, production work is started on the source database. The remote database is started in a standby mode. Typically, in standby mode, the database is not available for transactions. All DBMSs switch log files at preconfigured time intervals or when a log file is full. The current log file is closed at the time of log switching, and a new log file is opened. When a log switch occurs, the closed log file is transmitted by the source host to the remote host. The remote host receives the log and updates the standby database. This process ensures that the standby database is consistent up to the last committed log. RPO at the remote site is finite and depends on the size of the log and the frequency of log switching. Available network bandwidth, latency, rate of updates to the source database, and the frequency of log switching should be considered when determining the optimal size of the log file.
Similar to LVM-based remote replication, the existing standard IP network can be used for replicating log files. Host-based log shipping requires low network bandwidth because it transmits only the log files at regular intervals.
Storage Array-based Remote Replication – 1
In storage array-based remote replication, the array-operating environment and resources perform and manage data replication. This relieves the burden on the host CPUs, which can be better used for applications running on the host. A source and its replica device reside on different storage arrays. Data can be transmitted from the source storage array to the target storage array over a shared or a dedicated network. Replication between arrays may be performed in synchronous, asynchronous, or disk-buffered modes.
In array-based synchronous remote replication, writes must be committed to the source and the target prior to acknowledging “write complete” to the production host. Additional writes on that source cannot occur until each preceding write has been completed and acknowledged. To optimize the replication process and to minimize the impact on application response time, the write is placed on cache of the two arrays. The storage arrays destage these writes to the appropriate disks later. If the network links fail, replication is suspended; however, production work can continue uninterrupted on the source storage array. The array operating environment keeps track of the writes that are not transmitted to the remote storage array. When the network links are restored, the accumulated data is transmitted to the remote storage array. During the time of network link outage, if there is a failure at the source site, some data will be lost, and the RPO at the target will not be zero.

Storage Array-based Remote Replication – 2
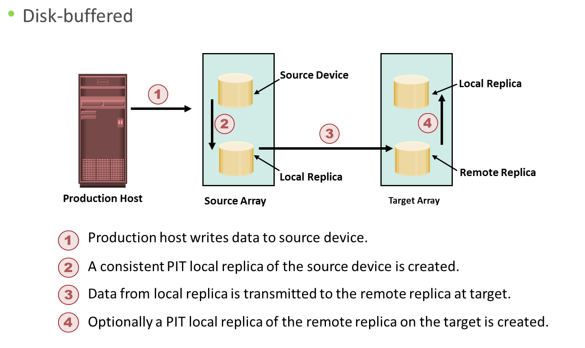
Disk-buffered replication is a combination of local and remote replication technologies. A consistent PIT local replica of the source device is first created. This is then replicated to a remote replica on the target array. Figure on the slide shows the sequence of operations in a disk-buffered remote replication. At the beginning of the cycle, the network links between the two arrays are suspended, and there is no transmission of data. While production application runs on the source device, a consistent PIT local replica of the source device is created. The network links are enabled, and data on the local replica in the source array transmits to its remote replica in the target array. After synchronization of this pair, the network link is suspended, and the next local replica of the source is created. Optionally, a local PIT replica of the remote device on the target array can be created. The frequency of this cycle of operations depends on the available link bandwidth and the data change rate on the source device. Because disk-buffered technology uses local replication, changes made to the source and its replica are possible to track. Therefore, all the resynchronization operations between the source and target can be done incrementally. When compared to synchronous and asynchronous replications, disk-buffered remote replication requires less bandwidth.
Network-based Replication – Continuous Data Protection
In network-based remote replication, the replication occurs at the network layer between the host and storage array. Continuous data protection technology, discussed in the previous module, also provides solutions for network-based remote replication. In normal operation CDP remote replication, provides any-point-in-time recovery capability, which enables the target LUNs to be rolled back to any previous point in time. Similar to CDP local replication, CDP remote replication typically uses journal volume, CDP appliance or CDP software installed on a separate host (host based CDP), and write splitter to perform replication between sites. The CDP appliance is maintained at both source and remote sites.
CDP Remote Replication Operation
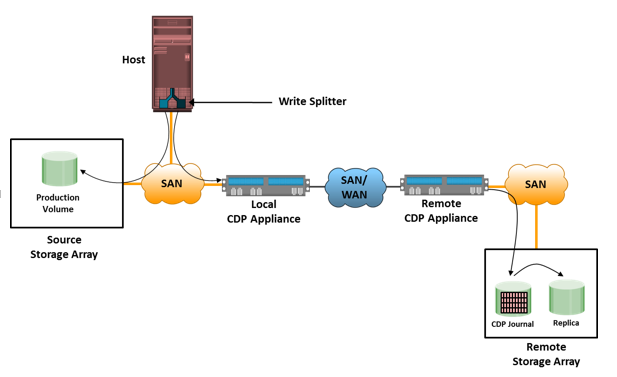
Figure describes CDP remote replication. In this method, the replica is synchronized with the source, and then the replication process starts. After the replication starts, all the writes from the host to the source are split into two copies. One of the copies is sent to the local CDP appliance at the source site, and the other copy is sent to the production volume. After receiving the write, the appliance at the source site sends it to the appliance at the remote site. Then, the write is applied to the journal volume at the remote site. For an asynchronous operation, writes at the source CDP appliance are accumulated, and redundant blocks are eliminated. Then, the writes are sequenced and stored with their corresponding timestamp. The data is then compressed, and a checksum is generated. It is then scheduled for delivery across the IP or FC network to the remote CDP appliance. After the data is received, the remote appliance verifies the checksum to ensure the integrity of the data. The data is then uncompressed and written to the remote journal volume. As a next step, data from the journal volume is sent to the replica at predefined intervals.
In the asynchronous mode, the local CDP appliance instantly acknowledges a write as soon as it is received. In the synchronous replication mode, the host application waits for an acknowledgment from the CDP appliance at the remote site before initiating the next write. The synchronous replication mode impacts the application’s performance under heavy write loads.
Three-site Replication
In synchronous replication, the source and target sites are usually within a short distance. Therefore, if a regional disaster occurs, both the source and the target sites might become unavailable. This can lead to extended RPO and RTO because the last known good copy of data would need to come from another source, such as an offsite tape library.
A regional disaster will not affect the target site in asynchronous replication because the sites are typically several hundred or several thousand kilometers apart. If the source site fails, production can be shifted to the target site, but there is no further remote protection of data until the failure is resolved.
Three-site replication mitigates the risks identified in two-site replication. In a three-site replication, data from the source site is replicated to two remote sites. Replication can be synchronous to one of the two sites, providing a near zero-RPO solution, and it can be asynchronous or disk buffered to the other remote site, providing a finite RPO. Three-site remote replication can be implemented as a cascade/multihop or a triangle/multitarget solution.
Three-site Replication: Cascade/Multihop
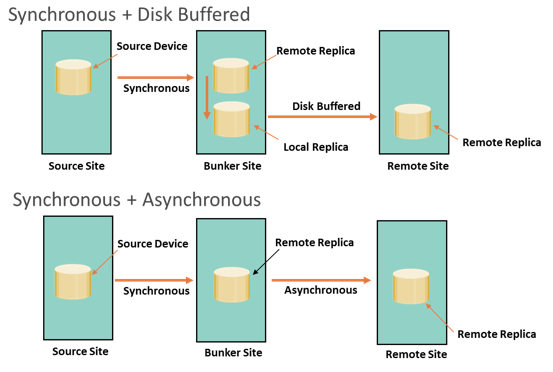
In the cascade/multihop three-site replication, data flows from the source to the intermediate storage array, known as a bunker, in the first hop, and then, from a bunker to a storage array at a remote site in the second hop. Replication can be performed in two ways, synchronous+ disk-buffered or synchronous+asynchronous.
- Synchronous + Disk Buffered: This method employs a combination of local and remote replication technologies. Synchronous replication occurs between the source and the bunker; a consistent PIT local replica is created at the bunker. Data is transmitted from the local replica at the bunker to the remote replica at the remote site. Optionally, a local replica can be created at the remote site after data is received from the bunker. In this method, a minimum of 4 storage volumes are required (including the source) to replicate one storage device. RPO at the remote site is usually in the order of hours for this implementation.
- Synchronous + Asynchronous: Synchronous replication occurs between the source and the bunker. Asynchronous replication occurs between the bunker and the remote site. The replica in the bunker acts as the source for asynchronous replication to create a remote replica at the remote site. RPO at the remote site is usually in the order of minutes. In this method, a minimum of 3 storage volumes are required (including the source). If a disaster occurs at the source, production operations are failed over to the bunker site with zero or near-zero data loss. If there is a disaster at the bunker site or if there is a network link failure between the source and bunker sites, the source site will continue to operate as normal but without any remote replication. This situation is very similar to remote site failure in a two-site replication solution. The updates to the remote site cannot occur due to the failure in the bunker site. Therefore, the data at the remote site keeps falling behind, but the advantage here is that if the source fails during this time, operations can be resumed at the remote site. RPO at the remote site depends on the time difference between the bunker site failure and source site failure.
A regional disaster in cascade/multihop replication is similar to a source site failure in two-site asynchronous replication. Operations are failover to the remote site with an RPO in the order of minutes. There is no remote protection until the regional disaster is resolved. Local replication technologies could be used at the remote site during this time. If a disaster occurs at the remote site, or if the network links between the bunker and the remote site fail, the source site continues to work as normal with disaster recovery protection provided at the bunker site.
Storage Array-based Remote Replication – 1
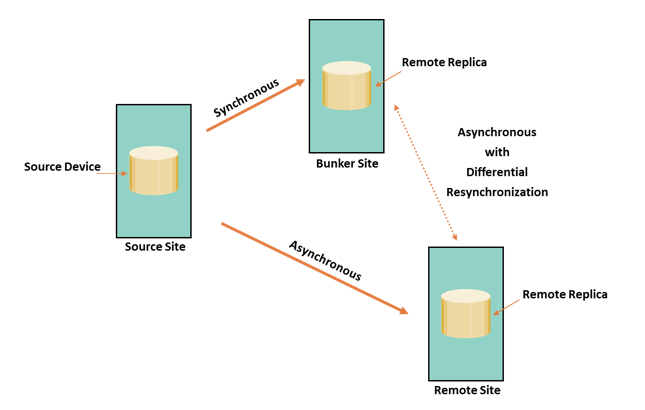
In three-site triangle/multitarget replication, data at the source storage array is concurrently replicated to two different arrays at two different sites, as shown in the figure. The source-to-bunker site (target 1) replication is synchronous with a near-zero RPO. The source-to-remote site (target 2) replication is asynchronous with an RPO in the order of minutes. The distance between the source and the remote sites could be thousands of miles. This implementation does not depend on the bunker site for updating data on the remote site because data is asynchronously copied to the remote site directly from the source. The triangle/multitarget configuration provides consistent RPO unlike cascade/multihop solutions in which the failure of the bunker site results in the remote site falling behind and the RPO increasing. The key benefit of three-site triangle/multitarget replication is the ability to failover to either of the two remote sites in the case of source-site failure, with disaster recovery (asynchronous) protection between the bunker and remote sites. Disaster recovery protection is always available if any one-site failure occurs.
During normal operations, all three sites are available and the production workload is at the source site. At any given instant, the data at the bunker and the source is identical. The data at the remote site is behind the data at the source and the bunker. The replication network links between the bunker and remote sites will be in place but not in use. The difference in the data between the bunker and remote sites is tracked, so that if a source site disaster occurs, operations can be resumed at the bunker or the remote sites with incremental resynchronization between these two sites.
A regional disaster in three-site triangle/multitarget replication is very similar to a source site failure in two-site asynchronous replication. If failure occurs, operations failover to the remote site with an RPO in the order of minutes. There is no remote protection until the regional disaster is resolved.
A failure of the bunker or the remote site is not really considered as a disaster because the operation can continue uninterrupted at the source site while remote DR protection is still available. A network link failure to either the source-to-bunker or the source-to-remote site does not impact production at the source site while remote DR protection is still available with the site that can be reached.
Data Migration Solution
A data migration and mobility solution is a specialized replication technique that enables creating remote point-in-time copies. These copies can be used for data mobility, migration, content distribution, and disaster recovery. This solution moves data between heterogeneous storage arrays. This technology is application-and server-operating-system independent because the replication operations are performed by one of the storage arrays.
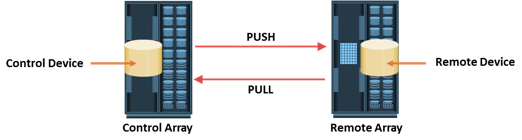
The array performing the replication operations is called the control array. Data can be moved from/to devices in the control array to/from a remote array. The terms control or remote do not indicate the direction of data flow; they indicate only the array that is performing the replication operation. Data migration solutions perform push and pull operations for data movement. These terms are defined from the perspective of the control array. In the push operation, data is moved from the control array to the remote array. In the pull operation, data is moved from the remote array to the control array.
When a push or pull operation is initiated, the control array creates a protection bitmap to track the replication process. Each bit in the protection bitmap represents a data chunk on the control device. When the replication operation is initiated, all the bits are set to one, indicating that all the contents of the source device need to be copied to the target device. As the replication process copies data, the bits are changed to zero, indicating that a particular chunk has been copied. During the push and pull operations, host access to the remote device is not allowed because the control array has no control over the remote array and cannot track any change on the remote device. Data integrity cannot be guaranteed if changes are made to the remote device during the push and pull operations. The push/pull operations can be either hot or cold. These terms apply to the control devices only. In a cold operation, the control device is inaccessible to the host during replication. Cold operations guarantee data consistency because both the control and the remote devices are offline. In a hot operation, the control device is online for host operations. During hot push/pull operations, changes can be made to the control device because the control array can keep track of all changes, and thus ensure data integrity.
Remote Replication/Migration in Virtualized Environment
In a virtualized environment, the data residing in a virtual volume is replicated (mirrored) to two storage arrays located at two different sites. Virtual machine migration is another technique used to ensure business continuity in case of hypervisor failure or scheduled maintenance. VM migration is the process of moving VMs from one location to another without powering off the virtual machines. VM migration also helps in load balancing when multiple virtual machines running on the same hypervisor contend for resources. Two commonly used techniques for VM migration are hypervisor-to-hypervisor and array-to-array migration.
Remote Mirroring of Virtual Volume
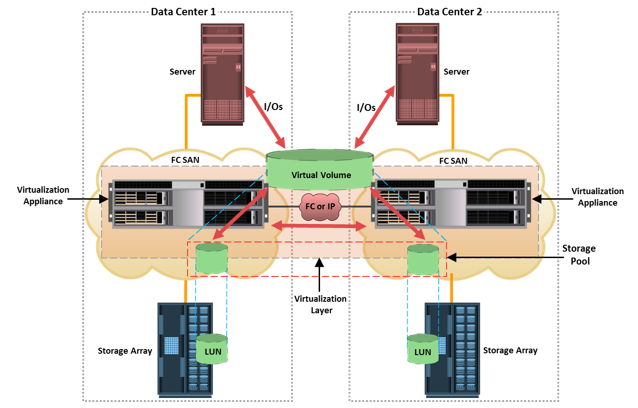
Virtualization enables mirroring of a virtual volume data between data centers. It provides the capability to connect the virtualization layers (appliance) at multiple data centers. The connected virtualization layers are managed centrally and work as a single virtualization layer that is stretched across data centers. The virtual volumes are created from the federated storage resources across datacenters. The virtualization appliance has the ability to mirror the data of a virtual volume between the LUNs located in two different storage arrays at different locations. Figure on the slide provides an illustration of a virtual volume that is mirrored between arrays across data centers. Each I/O from a host to the virtual volume is mirrored to the underlying LUNs on the arrays. If an outage occurs at one of the data centers, the virtualization appliance will be able to continue processing I/O on the surviving mirror leg. Data on the virtual volume can be mirrored synchronously or asynchronously.
VM Migration: Hypervisor-to-Hypervisor
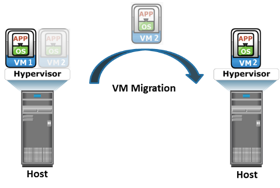
In hypervisor-to-hypervisor VM migration, the entire active state of a VM is moved from one hypervisor to another. This method involves copying the contents of virtual machine memory from the source hypervisor to the target and then transferring the control of the VM’s disk files to the target hypervisor. Because the virtual disks of the VMs are not migrated, this technique requires both source and target hypervisor access to the same storage.
VM Migration: Array-to-Array
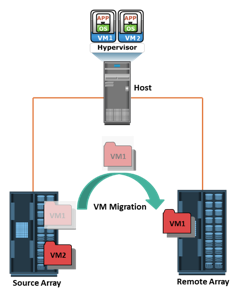
In array-to-array VM migration, VM files are moved from the source array to the remote array. This approach enables the administrator to move VMs across dissimilar storage arrays. Array-to-array migration starts by copying the metadata about the VM from the source array to the target. The metadata essentially consists of configuration, swap, and log files. After the metadata is copied, the VM disk file is replicated to the new location. During replication, there might be a chance that the source is updated; therefore, it is necessary to track the changes on the source to maintain data integrity. After the replication is complete, the blocks that have changed since the replication started are replicated to the new location. Array-to-array VM migration improves performance and balances the storage capacity by redistributing virtual disks to different storage devices.
EMC SRDF
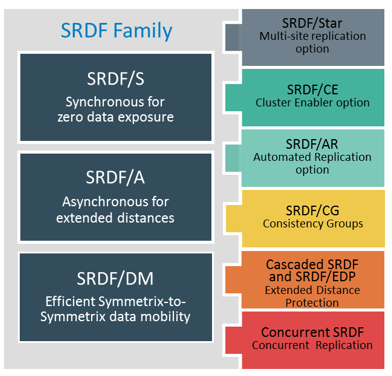 SRDF offers a family of technology solutions to implement storage array-based remote replication. The SRDF family of software includes the following:
SRDF offers a family of technology solutions to implement storage array-based remote replication. The SRDF family of software includes the following:
- SRDF/Synchronous (SRDF/S): A remote replication solution that creates a synchronous replica at one or more Symmetrix targets located within campus, metropolitan, or regional distances. SRDF/S provides a no-data-loss solution (near zero RPO) if a local disaster occurs.
- SRDF/Asynchronous (SRDF/A): A remote replication solution that enables the source to asynchronously replicate data. It incorporates delta set technology, which enables write ordering by employing a buffering mechanism. SRDF/A provides minimal data loss if a regional disaster occurs.
- SRDF/DM: A data migration solution that enables data migration from the source to target volume over extended distances.
- SRDF/Automated Replication (SRDF/AR): A remote replication solution that uses both SRDF and TimeFinder/Mirror to implement disk-buffered replication technology. It is offered as SRDF/AR Single-hop for two-site replication and SRDF/AR Multi-hop for three-site cascade replication. SRDF/AR provides long distance solution with RPO in the order of hours.
- SRDF/Star: Three-site multi-target remote replication solution that consists of primary (production), secondary (bunker), and tertiary (remote) sites. The replication between the primary and secondary sites is synchronous, whereas the replication between the primary and tertiary sites is asynchronous. In the event of primary site outage, EMC’s SRDF/Star solution allows to quickly move operations and re-establish remote replication between the remaining two sites.
EMC MirrorView
The MirrorView software enables EMC VNX storage array–based remote replication. It replicates the contents of a primary volume to a secondary volume that resides on a different VNX storage system. The MirrorView family consists of MirrorView/Synchronous (MirrorView/S) and MirrorView/Asynchronous (MirrorView/A) solutions.
MirrorView/S is a synchronous product that mirrors data between local and remote storage systems. MirrorView/A is an asynchronous product that offers extended distance replication based on periodic incremental update model. It periodically updates the remote copy of the data with all the changes that occurred on the primary copy since the last update.
EMC RecoverPoint
EMC RecoverPoint Continuous Remote Replication (CRR) provides bi-directional synchronous and asynchronous replication. In normal operations, RecoverPoint CRR enables users to recover data remotely to any point in time. RecoverPoint dynamically switches between synchronous and asynchronous replication based on the policy for performance and latency.


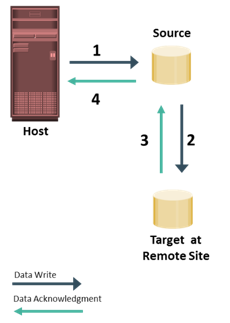
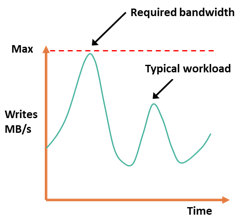
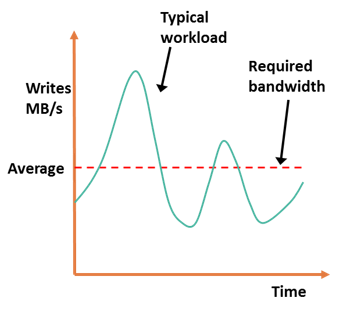
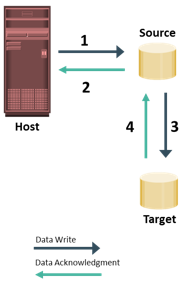 In asynchronous remote replication, a write is committed to the source and immediately acknowledged to the host. In this mode, data is buffered at the source and transmitted to the remote site later. Data at the remote site will be behind the source by at least the size of the buffer. Hence, asynchronous remote replication provides a finite (nonzero) RPO disaster recovery solution.
In asynchronous remote replication, a write is committed to the source and immediately acknowledged to the host. In this mode, data is buffered at the source and transmitted to the remote site later. Data at the remote site will be behind the source by at least the size of the buffer. Hence, asynchronous remote replication provides a finite (nonzero) RPO disaster recovery solution.