What is an
Why Business Continuity?
In today’s world, continuous access to information is a must for the smooth functioning of business operations. The cost of unavailability of information is greater than ever, and outages in key industries cost millions of dollars per hour. There are many threats to information availability, such as natural disasters, unplanned occurrences, and planned occurrences that could result in the inaccessibility of information. Therefore it is critical for businesses to define appropriate strategies that can help them to overcome these crises. Business continuity is an important process to define and implement these strategies.
What is an What is Business Continuity?
Business Continuity (BC)
It is a process that prepares for, responds to, and recovers from a system outage that can adversely affects business operations.
Business continuity (BC) is an integrated and enterprise-wide process that includes all activities (internal and external to IT) that a business must perform to mitigate the impact of planned and unplanned downtime. BC entails preparing for, responding to, and recovering from a system outage that adversely affects business operations. It involves proactive measures, such as business impact analysis, risk assessments, BC technology solutions deployment (backup and replication), and reactive measures, such as disaster recovery and restart, to be invoked in the event of a failure. The goal of a BC solution is to ensure the “information availability” required to conduct vital business operations.
In a virtualized environment, BC technology solutions need to protect both physical and virtualized resources. Virtualization considerably simplifies the implementation of BC strategy and solutions.
What is an Intelligent Storage System (ISS)?
Information Availability (IA)
It is the ability of an IT infrastructure to function according to business expectations, during its specified time of operation.
IA ensures that people (employees, customers, suppliers, and partners) can access information whenever they need it. IA can be defined in terms of the accessibility, reliability, and timeliness of the information.
- Information should be accessible to the right user when required.
- Information should be reliable and correct in all aspects. It is “the same” as what was stored and there is no alternation or corruption to the information.
- Defines the time window (a particular time of the day, week, month, and year as specified) during which information must be accessible. For example, if online access to an application is required between 8:00 am and 10:00 pm each day, any disruptions to data availability outside of this time slot are not considered to affect timeliness.
What is an Causes of Information Unavailability
Various planned and unplanned incidents result in information unavailability. Planned outagesinclude installation/integration/maintenance of new hardware, software upgrades or patches, taking backups, application and data restores, facility operations (renovation and construction), and refresh/migration of the testing to the production environment. Unplanned outagesinclude failure caused by human errors, database corruption, and failure of physical and virtual components.
Another type of incident that may cause data unavailability is natural or man-made disasters, such as flood, fire, earthquake, and so on.
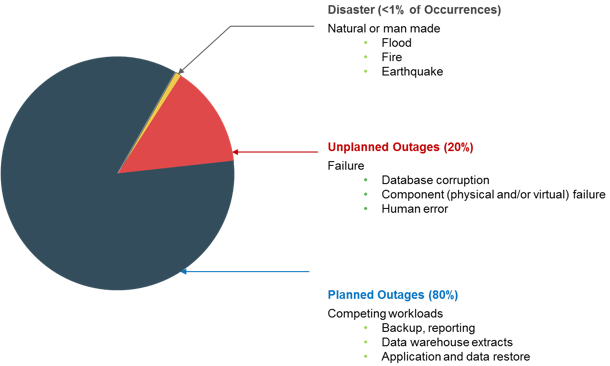
As illustrated in figure, the majority of outages are planned. Planned outages are expected and scheduled but still cause data to be unavailable. Statistically, the cause of information unavailability due to unforeseen disasters is less than 1 percent.
Impact of Downtime
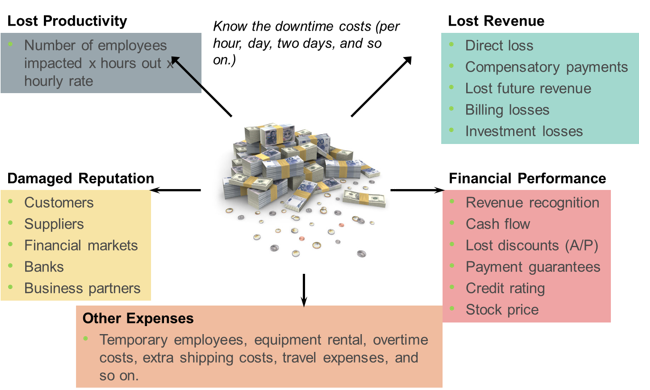
Information unavailability or downtime results in loss of productivity, loss of revenue, poor financial performance, and damages to reputation. Loss of productivity include reduced output per unit of labor, equipment, and capital. Loss of revenue includes direct loss, compensatory payments, future revenue loss, billing loss, and investment loss. Poor financial performance affects revenue recognition, cash flow, discounts, payment guarantees, credit rating, and stock price. Damages to reputations may result in a loss of confidence or credibility with customers, suppliers, financial markets, banks, and business partners. Other possible consequences of downtime include the cost of additional equipment rental, overtime, and extra shipping.
The business impact of downtime is the sum of all losses sustained as a result of a given disruption. An important metric, average cost of downtime per hour, provides a key estimate in determining the appropriate BC solutions. It is calculated as follows:
Average cost of downtime per hour = average productivity loss per hour + average revenue loss per hour
Where:
Productivity loss per hour = (total salaries and benefits of all employees per week) / (average number of working hours per week)
Average revenue loss per hour = (total revenue of an organization per week) / (average number of hours per week that an organization is open for business)
The average downtime cost per hour may also include estimates of projected revenue loss due to other consequences, such as damaged reputations, and the additional cost of repairing the system.
Measuring Information Availability (ISS)?
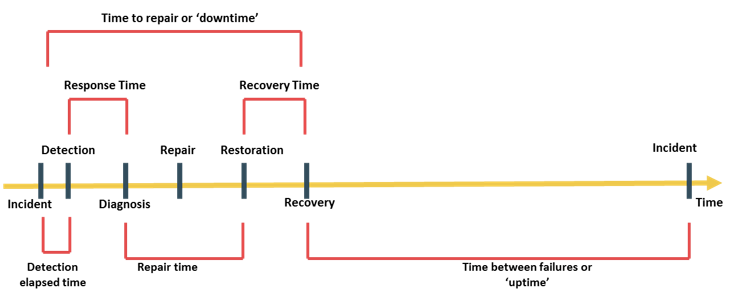
Information availability relies on the availability of both physical and virtual components of a data center. Failure of these components might disrupt information availability. A failure is the termination of a component’s ability to perform a required function. The component’s ability can be restored by performing an external corrective actions, such as a manual reboot, a repair, or replacement of the failed component(s). Proactive risk analysis, performed as part of the BC planning process, considers the component failure rate and average repair time, which are measured by MTBF and MTTR:

MTTR is calculated as: Total downtime/Number of failures
Information Availability (IA) can be expressed in terms of system uptime and downtime and measured as the amount or percentage of system uptime:
IA= system uptime / (system uptime + system downtime)
Where system uptimeis the period of time during which the system is in an accessible state; when it is not accessible, it is termed as system downtime.
In terms of MTBF and MTTR, IA could also be expressed as: IA = MTBF / (MTBF + MTTR)

Availability Measurement – Levels of ‘9s’ Availability
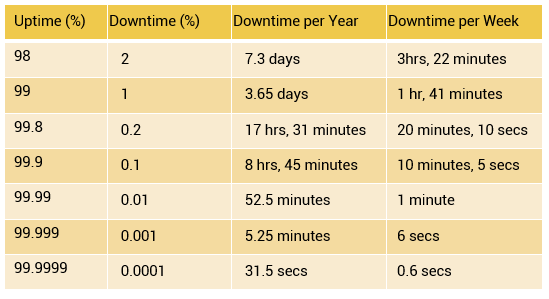
Uptime per year is based on the exact timeliness requirements of the service. This calculation leads to the number of “9s” representation for availability metrics. Table on the slide lists the approximate amount of downtime allowed for a service to achieve certain levels of 9s availability.
For example, a service that is said to be “five 9s available” is available for 99.999 percent of the scheduled time in a year (24 ×365).


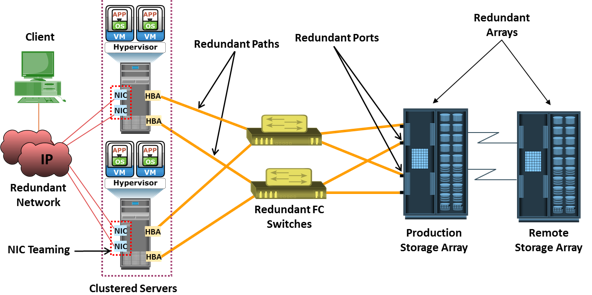
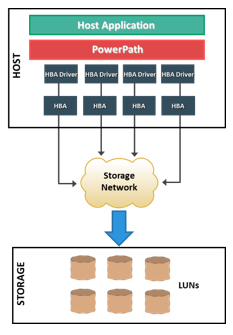 EMC PowerPath
EMC PowerPath 

